



欢迎关注“创事记”微信订阅号:sinachuangshiji
演讲/赖力鹏 文/李莹
来源:造就(ID:xingshu100)
一个残酷的事实是,我们已研发出的药物,与现存的疾病数目相比,可谓是九牛一毛,有许多疾病至今无药可治,而新的疾病、病毒又层出不穷,比如我们眼下正在经历的新型冠状病毒肺炎。
我们如何才能提升新药研发的效率?也许人工智能可以?
传统的新药研发过程是怎样的?它有两个特点:第一,周期特别长;第二,体系非常复杂。
一个药物的发现,首先需要在生物学上确定可能产生疾病的原因,然后到各种可能的分子当中去寻找,找到合适的药物,最后在医学上临床测试。
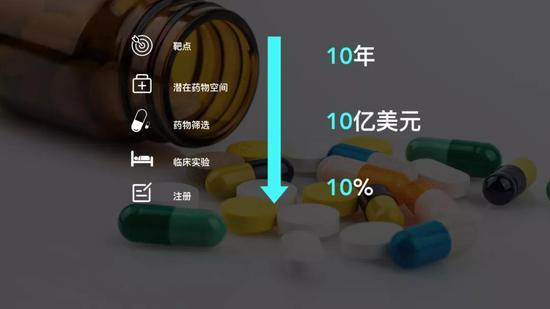
传统药物的研发过程
前后平均下来,可能要花超过10年时间,总体的投入会超过10亿美元,但成功率可能还不到10%。
1901年,我们人类第一次确诊阿尔兹海默症,到2019年已经经过了100多年的时间,我们依然没有能够找到有效的治疗方法。(阿尔茨海默症,一种神经退行性疾病,多发于老年,出现记忆障碍、失语、失去认知能力等是该疾病主要表现)我们等待了100年,还是没有找到更好的药。
《Nature》在2017年有篇文章叫The drug-maker’s guide to the galaxy,它给了我们一个新的希望:经过化学家的分析,在整个化学空间里面,我们可以找到的药物分子的个数,可能性是10的60次方。

整个化学空间中可以找到的药物分子的个数,可能性是10的60次方
什么概念呢,我们太阳系里面所有的原子加到一起,数量大概是10的54次方,所以这不单单是54和60的区别,这是一个指数级的差别。
而我们在传统实验室里,通过传统的药物筛选办法能够接触到的分子数量,大概在10的11次方,11和60,这两个数字中间,存在着一个巨大的差异。
就像我们要探索的可能是整个太阳系里所有的原子,我们要把每个原子都拿起来,看一看这个原子到底能不能成为药物,但我们现在实验室里能够接触到的原子,大概可能就是不到这个屋子这么大的一个范围里的原子数量。

赖力鹏在造就演讲
这篇文章中还提到,在人类的实验室里,我们没有办法真的把这些分子全部合成出来,那么虚拟的手段,或者人工智能手段,可能是我们下一个阶段寻找新药的努力方向。
《复仇者联盟》里面有个角色叫蚁人,蚁人可以把自己缩小到叫量子力学的尺度,在电影里他可以在这个尺度看到一个非常奇幻的世界。
现在其实不需要到量子力学尺度,阿伏加德罗定律告诉我们,我们周围大概20升的气体里面大约有10的23次方个分子,假设这些分子都各不相同,我们想做的就是在这么大量的分子数目里面,去找到那个和我们所遇到的疾病、我们所遇到的挑战,能够相匹配的药物分子。
类似于我们去问在宇宙中10的25次方个恒星当中,存不存在另外一个人类可以居住的星系?在这么大规模的潜在药物分子里面,我们能不能找到一个真的能够治愈我们疾病的分子?
如果有,我们怎么找到它?
我们把这个问题拆成两个部分:
第一,如何构造一个虚拟的化学空间?现在很多的化合物,包括层出不穷的新药,它本来在自然界中是不存在的,那么我们需要想出怎样把它构造出来的办法。
第二,在这10的60次方的空间里面,我们怎么找到真的能够成为药物的分子?
当我们真的走近第一个问题去看的时候,我们就发现,首先在工程上这是一件很难的事情,我们假设每一个药物分子,可以用一个比特来存储,这已经是一个很理想的假设,因为一个分子,它可能并不是只有0和1两个状态,这里只是一个简化的假设。
目前像Facebook这么庞大的社交网络,它所有的数据加起来,大概在10的18次方的比特左右。假设我们地球上每一个人,都拥有Facebook这么大的存储能力,我们大概有100亿人,也就是10的10次方,每个人有10的18次方的存储能力,所以我们拥有接近10的28次方的存储能力。
我们需要的空间是多大呢,10的60次方。所以这就意味着——我们要在宇宙当中对应每一个恒星有100亿人,然后每一个人,都拥有像Facebook这样的存储能力,我们才能把这些数据存下来。

10的60次方意味着什么
再假设,我们突然有了一个特别好的高科技,我们能把这些数据全部储存下来,我们的处理能力也不够。
现在我们经常处理的一个庞大的虚拟化合物库的数据量,大概可能到1000亿的范围。而在1000亿的可能性当中寻找到药物分子的处理时间,大概需要几天时间。
所以当数据从1000亿,也就是10的11到12次方,增加到10的60次方的时候,它已经是一个比一般概念的天文数字更大的一个数字。现有的计算能力,我们还没有办法处理这么庞大的数据。
我们会关注新的计算方法,比如说量子计算的出现,会不会在这种暴力美学的情况下,给我们带来一些更多的可能性。但在新的计算方法还没有出现之前,我们还需要想办法。
我们提出一个设想,10的60次方的化学分子,是不是都是有用的分子?
比如,现在针对阿尔兹海默症的药物,很显然在10的60次方里面,它们并不是都是对阿尔茨海默症有用的分子,我们只需要找到那些可能孤立的、但是每个分子都可能对阿尔茨海默症有用的小岛。

赖力鹏在造就演讲
面对着10的60次方的化合物空间,我们怎么样用一个更好的数学方法,把这些可能有用的化合物小岛找出来、表示出来?
一个药物能够成为药,它在多方面都必须是优秀的:有很好的药效,被很好地吸收,不具有毒性……我们就是要在这个空间当中,用这些条件去找到那些孤立的小岛,让我们发现药物的机会变得越来越大。
和传统的方法相比,我们具有模拟的优势:在对一个分子去做一些改变的时候,我们可以相对容易的用计算机产生几十万或者几百万和这个分子相似的一些分子,让它们能够具有相似的成药的可能性;
大家看这个分子,是我随便挑出来的,你们觉得这个分子长得漂亮吗?它像不像个药?
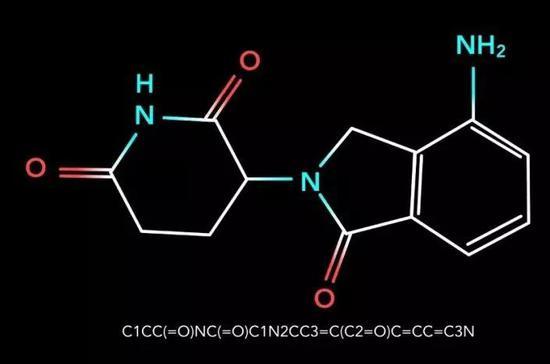
来那度胺
其实这个是一个已经成药的、非常重磅的抗肿瘤药物,叫来那度胺。它是美国Celgene公司在2005年上市的一个重磅药物,最近几年的年销售额应该是过几十亿美元。
化学、生物本身,它也有自己的语言规律,比如说碳可能最多连四个键,然后在药物里,可能我们更习惯看到苯环的出现等等。
熟悉这种语言,并针对这种大量的分子结构,做深度学习,人工智能就有可能学会这种化学分子结构的语言。
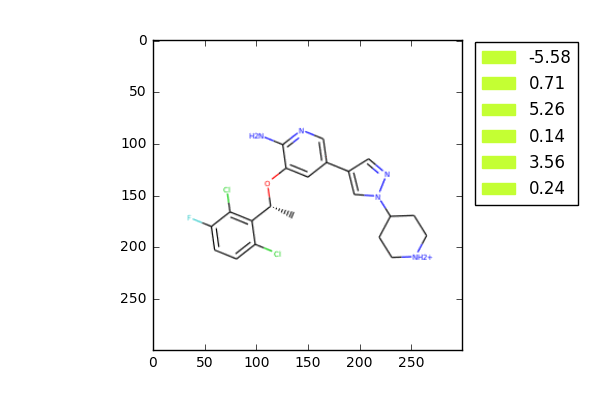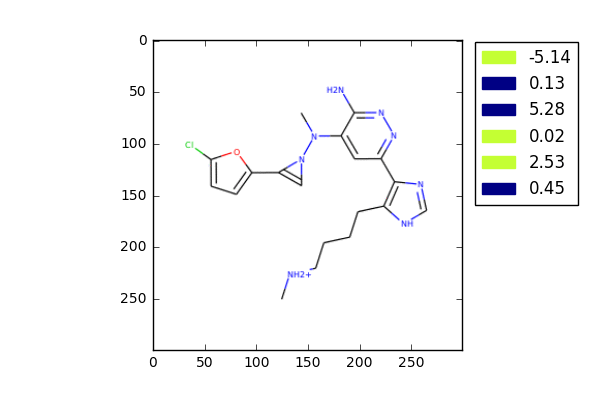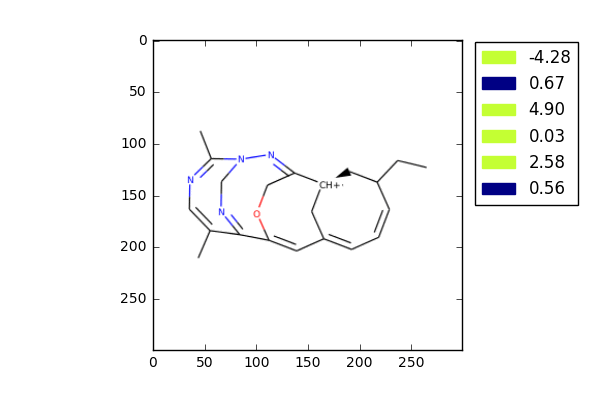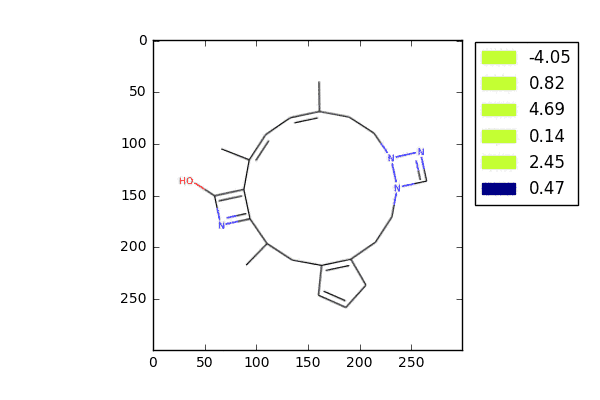
这是我们做的一个比较早期版本的一个人工智能,就像大家可能听过说人工智能可以作曲、画画,其实人工智能也可以画分子。
我们通过让机器学习了大量的分子结构数据之后,它学到了一些化学的知识,然后它开始去产生分子结构。
但我知道这些图画出来,如果有化学家看见,可能会把我拍在地上,其中有些分子的化学结构可能是非常不合理的。目前我们在这个最早期版本上已经做了很多的改进,让AI产生的分子尽可能符合药物设计的要求。
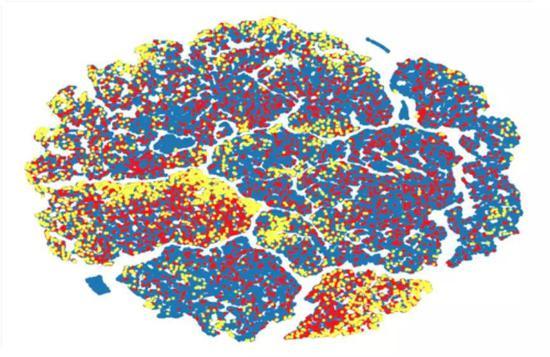
化合物空间分布示意图
这张图我非常喜欢,它特别像天空中的一些星图,它也特别像大脑。它是我们自己做出来的一张化合物空间分布示意图。
这个图上的每一个点代表一个分子结构:蓝色的点是我们用来训练人工智能所用到的我们的分子数据集。红色是人工智能学习完之后,去随机地产生不同的、新的分子结构的分布。
我们最想找到的是,去找到那些更可能成药的真正高质量的小岛。
就像Alpha Go或者Alpha Master,它们可以和自己对弈,不断强化,不断去纠正自己的习惯,从而下得越来越好一样。产生分子的人工智能也是,我们通过一定的规则去告诉它,我到底需要什么样的分子结构,那么它就可以去学习。
这张图上黄色的点,是我们对分子溶解度表现进行重点优化后筛选出来的分子。可以看到这些经过强化学习的黄色分子的分布,和红色的随机分布,产生了显著的不同。
我们其实是利用我们的化学手段,在尝试和人自身进行一场对话。
上个世纪的人类基因组计划是一个伟大的计划,是我们尝试在分子层面上去理解:
我们的生命是如何自我表达,我们的代际之间是怎么去沟通,我们如何通过遗传物质,让一代人和下一代人进行对话。
现代生物学已经知道,碱基可以形成DNA的序列,然后DNA通过生物学的过程,可以去指导蛋白质的合成,而蛋白质是由20种氨基酸按照一定的规律排列起来的,不同的排列可能会有不同的功能。
而我们已经可以用人工智能和计算的方法在一定程度上做到:你给我一个蛋白质序列,我可以告诉大家,它在三维空间当中会具有什么样的结构,而这个结构会怎样影响到生物的功能,不同的蛋白质之间通过三维的结构如何产生对话,从而去影响彼此。
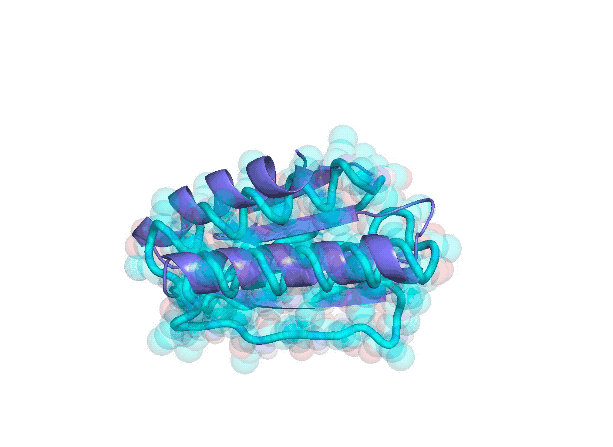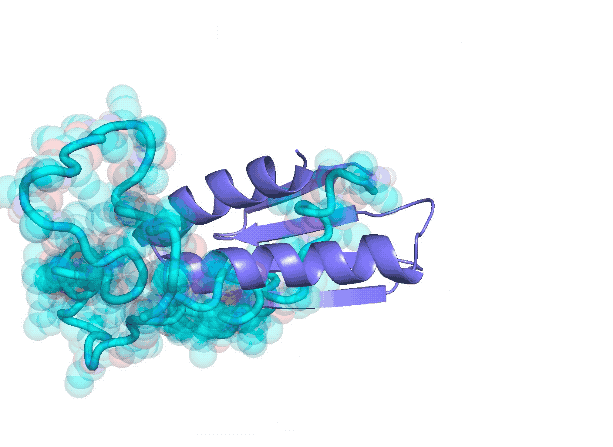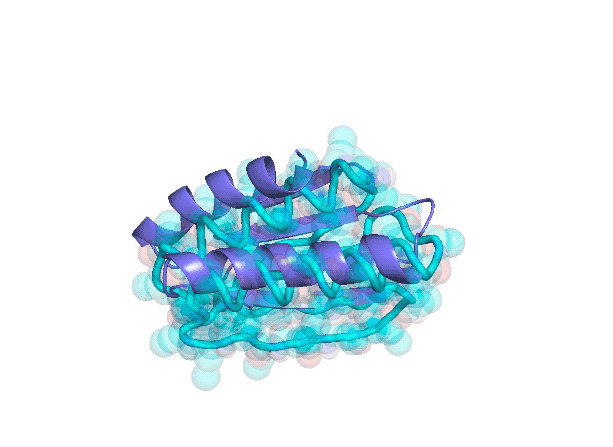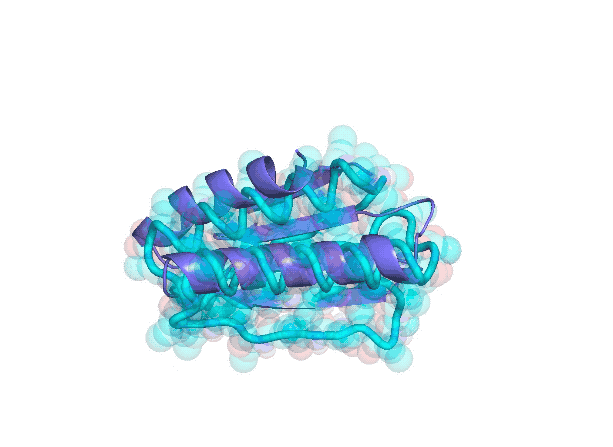
在虚拟空间计算得到的蛋白质的三维结构
下面这张图左边蓝色的部分是蛋白质,是生物学的理解,然后黄色的部分,是我们做的化学分子,是我们的化学语言。
药物研究是一场我们尝试与自身的“对话”
我们要做的事情就是,尝试理解生物学语言,尝试理解化学语言,然后把这两个语言合到一起,从而能够找到和疾病相关的蛋白质最匹配的那个化学分子,最终治愈我们的疾病。
刚才所讲的这些东西听起来很科幻,但它其实并不是神话。这里演示的是我们的实际案例,但图里面的结构不是真实案例中的。这里只是演示了我们利用人工智能进行早期药物发现的过程:
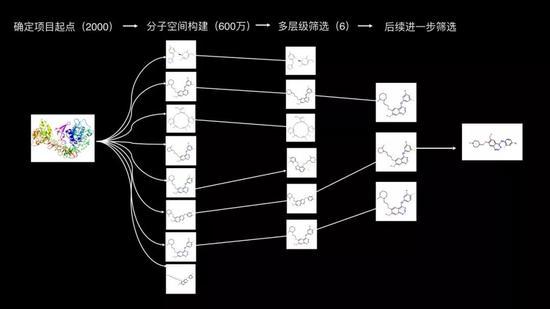
人工智能药物发现的流程
我们拿到了一个蛋白,然后我们可以用人工智能的方法去产生那些我们所感兴趣的、可能有用的化合物的空间,这个案例里我们产生了600万的化合物空间;然后我们基于对蛋白结构的理解,以及对小分子化合物的溶解度、毒性,在体内的吸收、代谢、排泄等属性进行同时的优化,最后我们留下了六个分子;然后这六个分子,在为期一个月的筛选过程中,最后的结果表现非常良好,可以进行到药物研发的下一个阶段。
这个项目我们在继续推进,在未来,新的药物很有可能会诞生在这六个分子当中。
这也是人工智能比传统的方法更有优势的地方,利用机器学习、人工智能的方法,能够在在非常早期,对未来将会成为药物的这些分子同时进行相对全面的判断,我们能提前筛掉后续实验会失败的分子。

赖力鹏在造就演讲
所以这就是为什么,人工智能用在新药发现上,有希望能极大地提高现在的发现效率和现在的成功率,我们可能有希望说,把现在需要三到四年才能完成的新药发现的前期过程,缩短到一年的时间就可以做完。
但回到现在现状本身,我们不得不充满敬畏地说,生物是一个非常复杂的体系。我们不认为说现在人工智能,可以单枪匹马完成整个新药发现的历程,我们更多认为人工智能,是在帮助我们更好地理解自己。
在整个新药发现的过程中,人工智能技术已和药物化学家一起合作,来让人类可以去发现更好的药物。
当然,在所有的药物发现创新过程中,计算只是一方面。我们可以看到还有其它大量的创新:机器人自动化的实验方法、基因检测技术和化合物筛选的结合、大规模的分子库的筛选方法,其实都在蓬勃的发展中。

药物发现创新过程中的创新
2019年美国FDA一共批准了48款新药,其中有20个是全新意义上的新药。
在药物创新这一块,大家都在努力,但是远远不够。在人工智能帮助我们发现新药的路径上,我们可能还是会面临很多挑战,比如如何把各个药企的数据结合到一起,利用更多高质量数据去做出更好的模型。
更重大的挑战是,当面临这样一个跨学科的复杂问题,在人工智能新药发现这个话题下面,我们会汇聚化学、生物、计算机、数学、统计等多个学科的人才,这些人怎么样才能够站到一起,彼此对话,彼此理解,而不是坚持己见,保有原来固有的思维方式。这个可能是我们需要解决的最大的困难。
阿西莫夫曾经在《永恒的终结》中说:

阿西莫夫《永恒的终结》中的一句话
用技术发现药物,也是这样。
