



△ CSAIL所在的MIT Building 32
欢迎关注“创事记”微信订阅号:sinachuangshiji
文/边策 问耕
来源:量子位(ID:QbitAI)
只听声音,就能知道一个人长什么样?
是的。
大名鼎鼎的麻省理工CSAIL(人工智能实验室),最近就发布了这样一个令人惊讶的研究。只需要听6秒的声音片段,AI就能推断出说话者的容貌。
怎么样?你行么?
MIT研究人员,设计和训练的神经网络Speech2Face,就能通过短短的语音片段,推测出说话者的年龄、性别、种族等等多重属性,然后重建说话人的面部。
下面就是AI听声识脸,给出的结果:
左边一列是真实的照片,右边一列是神经网络根据声音推断出来的长相。

讲真,这个效果让我们佩服。
这篇论文也入围了今年的学术顶级会议CVPR 2019。
当然这个研究也会引发一些隐私方面的担忧。不过研究团队在论文中特别声明,这个神经网络不追求完全精确还原单一个体的脸部图像。
不同的语言也有影响。论文中举了一个案例,同一男子分别说中文和英文,AI却分别还原出了不同的面孔样貌。当然,这也跟口音、发声习惯等相关。
另外,研究团队也表示,目前这套系统对还原白人和东亚人的面孔效果更好。可能由于印度和黑人的数据较少,还原效果还有待进一步提高。
原理
从声音推断一个人的长相不是一种玄学,平时我们在打电话时会根据对方的声音脑补出相貌特征。
这是因为,年龄、性别、嘴巴形状、面部骨骼结构,所有这些都会影响人发出的声音。此外,语言、口音、速度通常会体现出一个的民族、地域、文化特征。
AI正是根据语音和相貌的关联性做出推测。
为此,研究人员提取了几百万个YouTube视频,通过训练,让深度神经网络学习声音和面部的相关性,找到说话的人一些基本特征,比如年龄、性别、种族等,并还原出相貌。
而且在这个过程中,不需要人类标记视频,由模型自我监督学习。这就是文章中所说的Speech2Face模型。
将电话另一端通过卡通人物的方式显示在你的手机上,可能是Speech2Face未来的一种实际应用。

模型结构
Speech2Face模型是如何还原人脸的,请看下图:
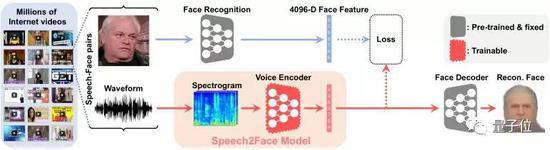
给这个网络输入一个复杂的声谱图,它将会输出4096-D面部特征,然后使用预训练的面部解码器将其还原成面部的标准图像。
训练模块在图中用橙色部分标记。在训练过程中,Speech2Face模型不会直接用人脸图像与原始图像进行对比,而是与原始图像的4096-D面部特征对比,省略了恢复面部图像的步骤。
在训练完成后,模型在推理过程中才会使用面部解码器恢复人脸图像。
训练过程使用的是AVSpeech数据集,它包含几百万个YouTube视频,超过10万个人物的语音-面部数据。
在具体细节上,研究使用的中每个视频片段开头最多6秒钟的音频,并从中裁剪出人脸面部趋于,调整到224×224像素。

△从原始图像提取特征重建的人脸,以及从声音推测的人脸
之前,也有人研究过声音推测面部特征,但都是从人的声音预测一些属性,然后从数据库中获取最适合预测属性的图像,或者使用这些属性来生成图像。
然而,这种方法存在局限性,需要有标签来监督学习,系统的鲁棒性也较差。
由于人脸图像中面部表情、头部姿态、遮挡和光照条件的巨大变化,想要获得稳定的输出结果,Speech2Face人脸模型的设计和训练变得非常重要。
一般从输入语音回归到图像的简单方法不起作用,模型必须学会剔除数据中许多不相关的变化因素,并隐含地提取人脸有意义的内部表示。
为了解决这些困难,模型不是直接得到人脸图像,而是回归到人脸的低维中间表示。更具体地说,是利用人脸识别模型VGG-Face,并从倒数第二层的网络提取一个4096-D面部特征。
模型的pipeline由两个主要部分组成:
1、语音编码器
语音编码器模块是一个CNN,将输入的语音声谱图转换成伪人脸特征,并预测面部的低维特征,随后将其输入人脸解码器以重建人脸图像。
2、面部解码器
面部解码器的输入为低维面部特征,并以标准形式(正面和中性表情)产生面部图像。
在训练过程中,人脸解码器是固定的,只训练预测人脸特征的语音编码器。语音编码器是作者自己设计和训练的模型,而面部解码器使用的是前人提出的模型。
将实验结果更进一步,Speech2Face还能用于人脸检索。把基于语音的人脸预测结果与数据库中的人脸进行比较,系统将给出5个最符合的人脸照片。
不足之处
若根据语言来预测种族,那么一个人说不同的语言会导致不同的预测结果吗?
研究人员让一个亚洲男性分别说英语和汉语,结果分别得到了2张不同的面孔。

模型有时候也能正确预测结果,比如让一个亚洲小女孩说英文,虽然恢复出的图像和本人有很大差距,但仍可以看出黄种人的面部特征。

研究人员表示,这个小女孩并没有明显的口音特征,所以他们的模型还要进一步检查来确定对语言的依赖程度。
在其他一些情况下,模型也会“翻车”。比如:变声期之前的儿童,会导致模型误判性别发生错误;口音与种族特征不匹配;将老人识别为年轻人,或者是年轻人识别为老人。

作者团队

这个研究的作者,大部分来自MIT CSAIL。
一作Tae-Hyun Oh是在CSAIL工作的Postdoctoral Associate,这个韩国小哥博士毕业于韩国科学技术院(KAIST),本科毕业于韩国光云大学(KWU)。他还曾经在微软亚洲研究院实习。
二作Tali Dekel现在是Google的一位研究员,之前也是CSAIL实验室的Postdoctoral Associate。她博士毕业于以色列的特拉维夫大学。
Tali Dekel还有一篇论文,也入选了今年的CVPR 2019,而且还拿到了Oral。在那篇论文里,她也是二作的身份。这篇论文昨天我们也报道了~
今年的CVPR将于6月16日在加州长滩召开。
最后,给一下传送门。
论文地址在此:
https://arxiv.org/pdf/1905.09773.pdf
项目地址在此:
https://speech2face.github.io/
作者
