


作者:David Salazar
编辑:陈萍、魔王
机器学习方法是预测的有力工具,但是很多领域的工作或研究重视对因果关系的讨论。相关性并不意味着因果关系,那么如何识别因果关系呢?

David Salazar 发布了一系列博客介绍因果关系。在之前的文章中,他将因果关系定义为干预分布(interventional distribution),并介绍了两种识别因果关系的策略:后门准则和前门准则。然而,这些准则并不适用于所有因果关系。
那么一般而言,给定因果模型和不完整的度量集,如何确定因果关系可识别呢?
本文提供了一种答案:利用 c-component (confounded component) 概念开发的图标准(graphical criterion),并通过多个实例进行演示。
马尔可夫模型
当我们可以得到因果模型中所有变量的度量值时,则该因果模型为马尔可夫模型。在这种情况下,调整公式(adjustment formula)就是识别策略:如果 X, Pa(X) 的父代存在度量值,则任意因果关系 X→Y 都是可识别的。
那么,如果你没有观察到 x 的父代呢?
半马尔可夫模型
如果一个未观察到的变量在图中有两个子代,则不符合马尔可夫属性。在这种情况下我们未必能够使用调整公式。例如,如果 X 的某个父代未被观察到,则我们无法将它作为识别策略。不过,我们或许仍可以使用后门或前门准则。
我们来看一个相关示例。在如下例子中,双向虚线表示变量之间的隐藏共同原因(hidden common cause)。U 表示所有未度量变量,V 表示所有观察到的变量。
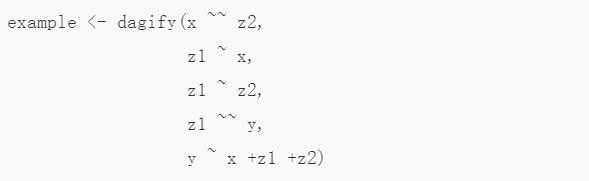
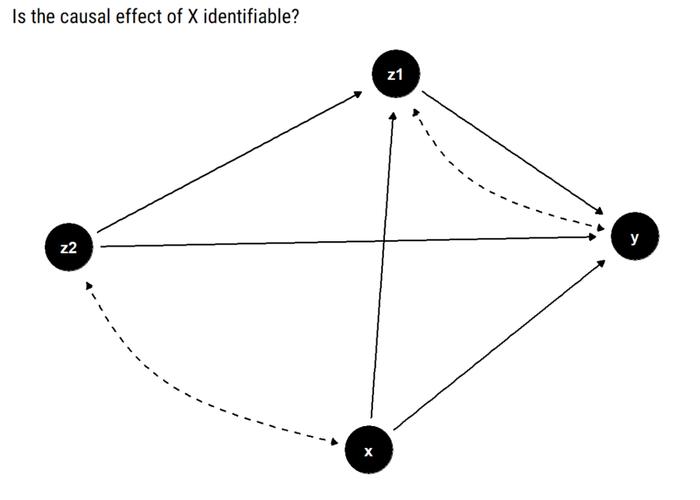
为了确定 X 对所有其他观测变量 v 的因果关系,我们必须根据观察到的干预前概率来估计干预后的概率 P(v|do(X))。
请记住这里的因果模型同时也是概率模型。特别是,它们导致了联合概率分布的分解。然而,当模型包含未观察到的混杂因素(confounder)时,我们必须将它们边缘化,以获得观测变量的联合概率分布:
在这种情况下,观测值的分解如下:
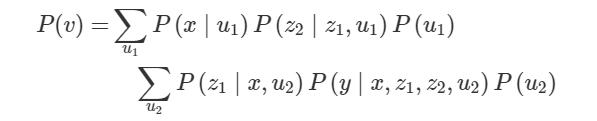
假设 P(v|do(X=x)) 表示干预,则它可以通过截断上述表达式进行表示,这样我们就不用计算 X 的概率了:
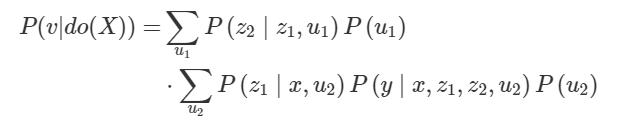
我们能使用观测变量表示 P(v|do(X)) 吗?首先,我们必须了解 confounded component。
confounded component
请注意,在这两个表达式中,未观察到的混杂因素将观察到的变量分成不相交的组:当且仅当两个变量通过双向路径连接时,它们才会被分配到同一组。在每一组中,S_k 被称为 confounded component (c-component)。在这种情况下存在两个 c-component,它们会引起两次因式分解 (c-factor):
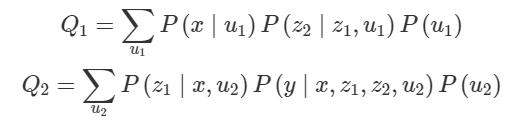
注意,在对所有其他变量进行干预的情况下,每个 (c-factor) Q_k 都可以解释为 S_k 中变量的干预后分布。我们可以将联合观测分布表示为 c-factor 的乘积:
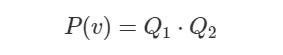
反过来,如果将 Q_1 中的 P(x|u_1) 边缘化,则我们可以用 Q_1、Q_2 来定义 P(v|do(X)):
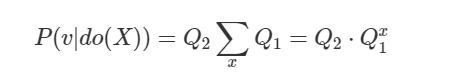
因此,P(v|do(X)) 是可识别的,前提是:a)我们可以根据干预前的概率计算干预后的概率 Q_1、Q_2;b)我们可以将 x 从估计的 Q_1 中边缘化,从而计算 Q_1^x。
事实上,Tian 和 Pearl 的研究《A General Identification Condition for Causal Effects》表明每个 c-factor 都是可识别的。因此,计算 P(v|do(X)) 的唯一条件是「当且仅当 Q_1^x 可识别」。在这种情况下:
因此,我们可以通过对 X 的值求和将 x 从 Q_1 中边缘化。
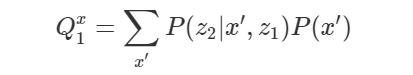
最后,对 P(v|do(X)) 的估计如下:
识别因果关系的通用标准
首先,请注意,对于任何具有双向路径的图,我们都可以通过划分 c-component 及其各自 c-factor 的方法,来分解联合概率分布:
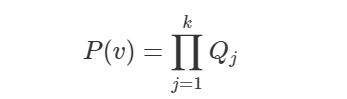
还需要注意的是,通过干预 x 生成的截断分布可以用 c-factor 来表示:
上式中,一旦从因式分解中删除了 x,则 Q_x^x 是 x 位置的 c-factor。因此,如果 Q_x^x 是可识别的,则 P(v|do(X=x) 也是可识别的。
实际上,Tian 和 Pearl 的研究表明,当且仅当不存在将 X 连接至其子代的双向路径(仅具有双向边的路径)时,Q_x^x 可识别。因此,我们可以得到以下测试,用于确定 P(v|do(X=x) 是否可识别:
当且仅当没有双向路径将 X 连接至它的任何子代时,P(v|do(X=x) 是可识别的。
注意,如果 P(v|do(X=x) 可识别,则 P(Y|do(X=x)) 也是可识别的。因此,这一标准足以确定 P(v|do(X=x) 是否不可识别。假设我们只对单个变量 Y 的因果关系感兴趣,那么我们可以只考虑 Y 的祖代变量的子图,来简化问题。
直观理解
如何直观地理解可识别性测试呢?可识别性的关键不在于阻止 X 和 Y 之间的后门路径,而是阻止 X 与其任何子代(即 Y 的祖代)之间的后门路径。因此,通过阻断这些路径,我们可以确定观察到的关联的哪一部分是虚假的,哪些是真正的因果关系。
接下来,我们来看应用示例。
示例 1
先看上文中的示例。为什么它是可识别的?该示例中所有其他变量都是 Y 的祖代,在这种情况下我们无法简化问题。因此,我们必须查看 X 和它的子代之间是否存在双向路径:
tidy_dagitty(example, layout = "nicely", seed = 2) %>%
node_descendants("x") %>%
mutate(linetype = if_else(direction == "->", "solid", "dashed")) %>%
ggplot(aes(x = x, y = y, xend = xend, yend = yend, color = descendant)) +
geom_dag_edges(aes(end_cap = ggraph::circle(10, "mm"), edge_linetype = linetype)) +
geom_dag_point() + geom_dag_text(col = "white") +
labs(title = "The causal effect of X is identifiable",
subtitle = "There's no bi-directed path between X and its descendats")
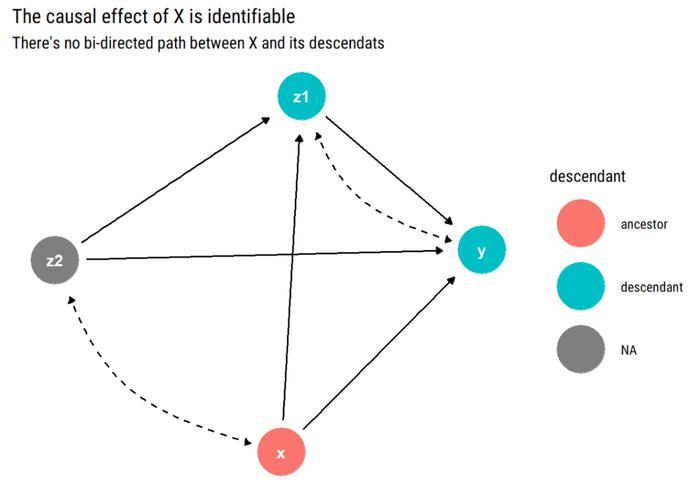
假设 X 和它的子代之间没有双向路径,则 X 的因果关系是可识别的。
示例 2
non_identifiable_example <- dagify(x ~ z,
x ~~~ z,
x ~~ y,
w ~ x,
w ~~ z,
y ~ w,
y ~~ z)
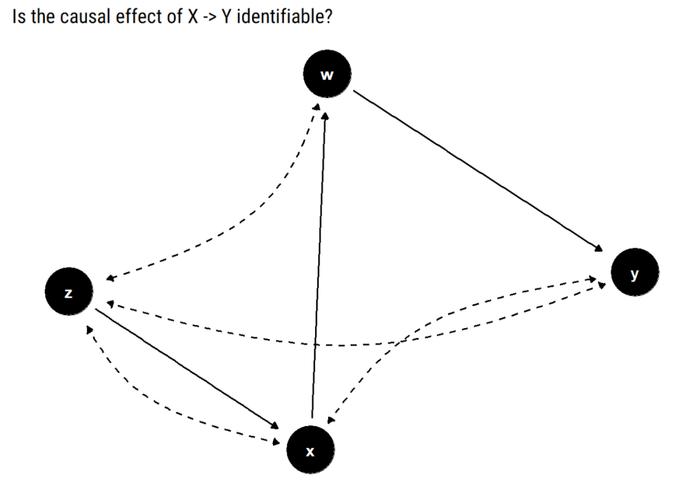
在本例中,为了确定因果关系是否可识别,我们需要寻找 X 及其子代之间的双向路径。如果没有,则因果关系可识别。
tidy_dagitty(non_identifiable_example, layout = "nicely", seed = 2) %>%
node_descendants("x") %>%
mutate(linetype = if_else(direction == "->", "solid", "dashed")) %>%
ggplot(aes(x = x, y = y, xend = xend, yend = yend, color = descendant)) +
geom_dag_edges(aes(end_cap = ggraph::circle(10, "mm"), edge_linetype = linetype)) +
geom_dag_point() + geom_dag_text(col = "white")
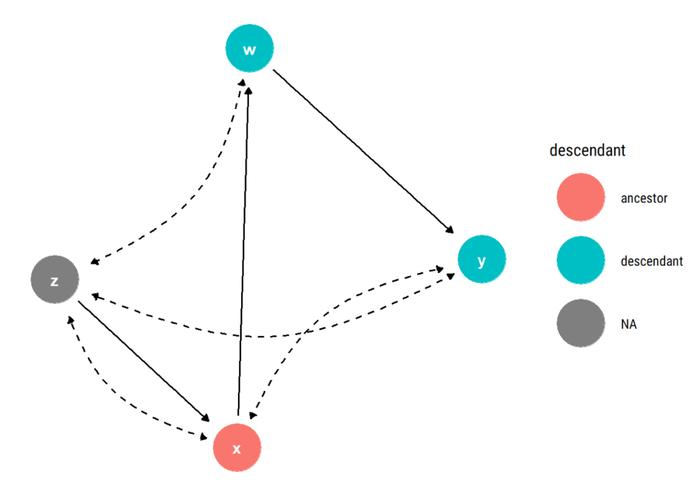
注意,在 X 和 W(X 的子代之一)之间存在一条经过 Z 的双向路径,根据上文介绍的图标准,其因果关系不可识别。
示例 3
third_example <- dagify(z1 ~ x + z2,
x ~ z2,
x ~~ z2,
x ~~ y,
z2 ~~ y,
z3 ~ z2,
x ~~ z3,
y ~ z1 + z3)
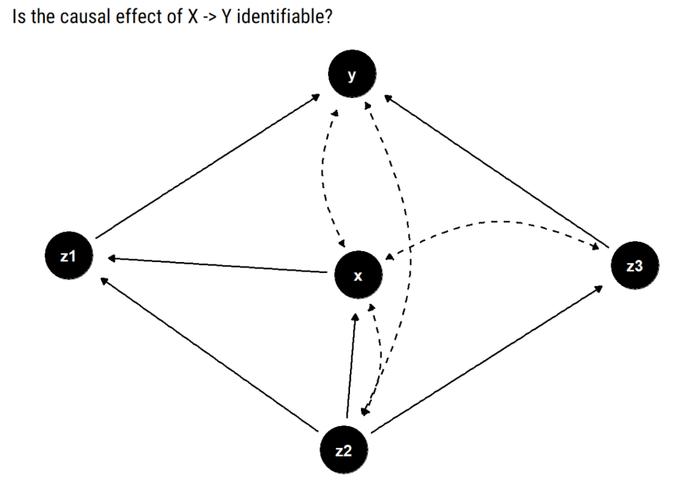
与前面的示例一样,本例中我们仍需在 X 及其子代之间寻找双向路径。
tidy_dagitty(third_example, layout = "nicely", seed = 2) %>%
node_descendants("x") %>%
mutate(linetype = if_else(direction == "->", "solid", "dashed")) %>%
ggplot(aes(x = x, y = y, xend = xend, yend = yend, color = descendant)) +
geom_dag_edges(aes(end_cap = ggraph::circle(10, "mm"), edge_linetype = linetype)) +
geom_dag_point() + geom_dag_text(col = "white")
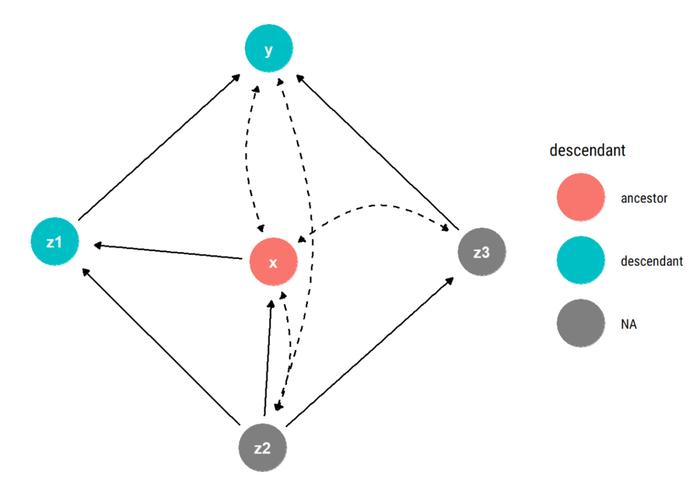
注意,X 与其 Y 以外的唯一子代(z1)没有双向路径。因此,其因果关系可识别。
可识别性的必要条件是什么?
对于可识别性,本文提到的测试是充分条件但并非必要条件。那么,是否存在充要条件呢?答案是肯定的,Pearl 和 Shipster(2006)提到了一种算法。它扩展了本文中的想法,根据干预前的概率返回因果关系的估计值。它是完备的且等效于 Pearl 的 do-calculus。
在 R 语言中,使用 causaleffect 软件包能够实现该算法。将其用于第一个示例,得到:
first_example_igraph <-graph.formula(x-+ z_2,
z_2-+ x,
x-+ z_1,
z_2-+ z_1,
z_1-+ y,
y-+ z_1,
x-+ y,
z_1-+ y,
z_2-+ y, simplify = FALSE) %>%
set.edge.attribute("description", index = c(1, 2, 5, 6), "U")
ce <-causal.effect(y = "y", x = "x", z = NULL,G = first_example_igraph,expr = TRUE)
plot(TeX(ce), cex = 3)
总结
在半马尔可夫模型中,变量之间存在隐藏共同原因,这些原因可能会破坏识别策略。本文介绍了一种对可识别性的充分测试方法,它基于隐藏共同原因的本质(用双向边来表示)。如果 X 和它的子代(也是 Y 的祖代)之间存在双向路径,则因果关系不可识别。
本文还提供了一个充分必要条件,并展示了如何在 R 语言中使用它。该条件是完备的,当因果关系可识别时,它返回一个估计量,可用于基于观测数据估计因果关系。
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
