


编辑:魔王、陈萍
本文介绍了微软开源的计算机视觉库,它囊括了计算机视觉领域的最佳实践、代码示例和丰富文档。

近年来,计算机视觉领域突飞猛进,在人脸识别、图像理解、搜索、无人机、地图、半自动和自动驾驶方面得到广泛应用。而这些应用的核心部分是视觉识别任务,如图像分类、目标检测和图像相似度。
在各种计算机视觉模型和应用层出不穷的当下,如何把握发展脉络,跟进领域前沿发展呢?微软创建了一个库,提供构建计算机视觉系统的大量示例和最佳实践指导原则。
项目地址:https://github.com/microsoft/computervision-recipes
这个库旨在构建一个全面的集合,涵盖利用了计算机视觉算法、神经架构和系统运行方面近期进展的工具和示例。
该库没有从头开始创建实现,而是基于已有的 SOTA 库发展而来,并围绕加载图像数据、优化和评估模型、扩展至云端构建了额外的工具函数。此外,微软团队表示,希望通过该项目回答计算机视觉领域的常见问题、指出频繁出现的缺陷问题,并展示如何利用云进行模型训练和部署。
该库中所有示例以 Jupyter notebooks 和常见工具函数的形式呈现。所有示例均使用 PyTorch 作为底层深度学习库。
Jupyter notebooks 地址:https://github.com/microsoft/computervision-recipes/blob/master/scenarios
工具函数地址:https://github.com/microsoft/computervision-recipes/blob/master/utils_cv
目标群体
该库的目标群体是具备一定计算机视觉知识背景的数据科学家和机器学习工程师,因为库的内容以 source-only(仅源代码)的形式呈现,支持自定义机器学习建模。这个库提供的工具函数和示例旨在为现实世界的视觉问题提供解决方案加速器。
示例
该库支持不同的计算机视觉场景,如基于单张图像运行,示例如下:

或基于视频序列的动作识别等场景,示例如下:
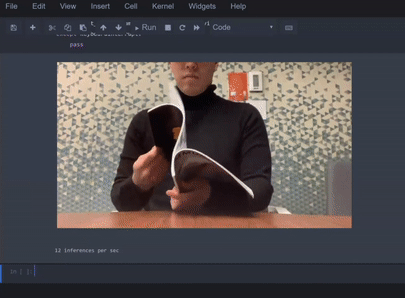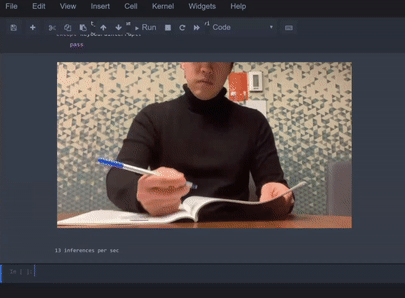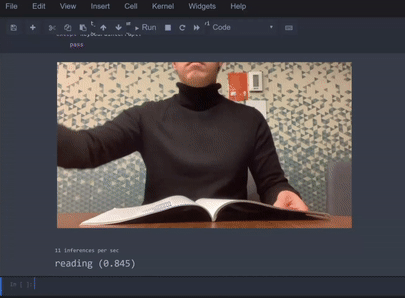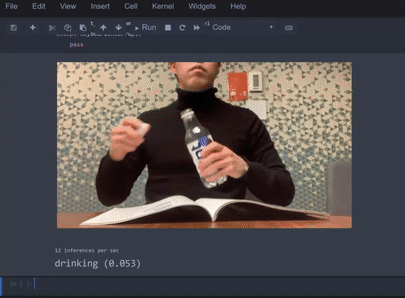
场景
该库涵盖常用的计算机视觉场景,包含如下类别:
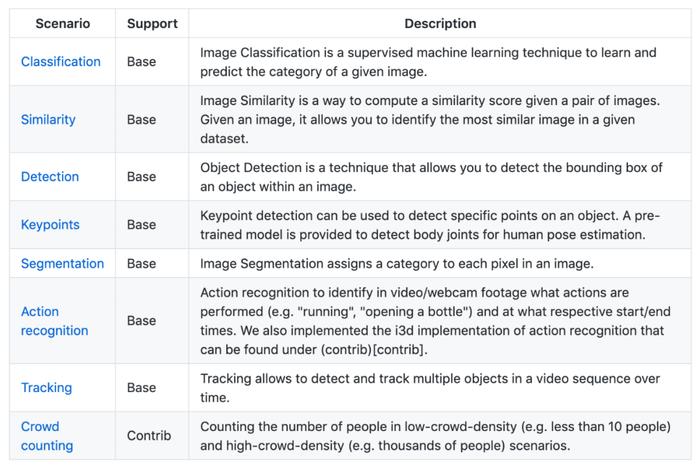
对于每个主要场景(base),该项目均提供使用户高效构建自己模型的工具。这需要使用者完成一些任务,如基于自己的数据微调模型的简单任务,或者难例挖掘甚至模型部署等更复杂的任务。
1. 图像分类任务
该目录提供了构建图像分类系统的示例和最佳实践,旨在让用户能够在自己的数据集上轻松快速地训练高准确率分类器。
这里提供的示例 notebook 具备预置的默认参数,可以很好地处理多个数据集。该目录还提供了有关常见缺陷和最佳实践的大量文档。
此外,该库还展示了如何使用微软的云计算平台 Azure,加快在大型数据集上的训练速度或将模型部署为 web 服务。

2. 图像相似度
该目录提供了构建图像相似度系统的示例和最佳实践,旨在使用户能够基于自己的数据集方便快捷地训练高精度模型。
下图为图像检索示例,其中左图为查询图像,右面为与之最相似的 6 幅图像:

3. 目标检测
该目录提供了构建目标检测系统的示例和最佳实践,旨在使用户能够基于自己的数据集方便快捷地训练高准确率模型。

该库使用了 torchvision 的 Faster R-CNN 实现,它被证明能够很好地处理多种计算机视觉问题。
项目作者建议使用者在具备 GPU 的机器上运行示例,虽然 GPU 在技术层面上并非必需,但是如果不使用 GPU,即使只用几十个图像,训练过程也会变得非常缓慢。
4. 关键点检测
该目录包含构建关键点检测系统的示例和最佳实践指导原则,并展示了如何使用预训练模型进行人体姿势估计。
该目录使用了 Mask R-CNN 的扩展,可以同时检测物体及其关键点。其底层技术与上述目标检测方法类似,即基于 Torchvision 的 Mask R-CNN。

5. 图像分割
该目录提供了构建图像分割系统的示例和最佳实践,旨在使用户能够基于自己的数据集方便快捷地训练高准确率模型。

这里的实现使用了 fastai 的 UNet 模型,其中 CNN 主干(如 ResNet)在 ImageNet 数据集上经过预训练,因此使用者只需少量标注训练样本就可以对其进行微调。
6. 动作识别
该目录包含构建基于视频的动作识别系统所需要的资源,旨在使用户能够在自定义数据集上轻松快速地训练出高准确率的快速模型。
动作识别(也叫「活动识别」)包括从一系列帧中对多种动作进行分类,例如「阅读」或「饮酒」:
动作识别是一个热门的研究领域,每年都有大量的方法发表。其中一个突出的方法是 R(2+1)D 模型,它能够获得高准确率,且比其他方法快得多。(参见论文《Large-scale weakly-supervised pre-training for video action recognition》)
该目录中的实现和预训练权重均基于这个 GitHub 库(https://github.com/moabitcoin/ig65m-pytorch),并添加了一些功能,以使自定义模型的训练和评估更加用户友好。这里在预训练时使用的是 IG-Kinetics 数据集。
7. 多目标跟踪
该目录提供了构建和推断多目标跟踪系统的示例和最佳实践,旨在使用户能够基于自定义数据集轻松训练高准确率跟踪模型。
该库集成了 FairMOT 跟踪算法,该算法在近期的 MOT 基准测试中表现出了很强的跟踪性能,同时也推理速度也很快。
8. 人群计数
该目录提供了多个人群计数算法的 production-ready 版本,不同算法被统一在一组一致性 API 下。

对多个基于专用数据集的人群计数模型实现进行评估后,该项目将模型范围缩小到两个选项:Multi Column CNN model (MCNN) 和 OpenPose 模型。二者均符合速度要求。
对于高密度人群图像,MCNN 模型取得了良好的效果;
对于低密度场景,OpenPose 表现良好。
而当人群密度未知时,该项目采用启发式方法。在满足以下条件时使用 MCNN 进行预测:OpenPose 预测大于 20,MCNN 大于 50。反之,则使用 OpenPose 预测。模型的阈值可以根据使用者的场景进行更改。
此外,该目录还展示了依赖项、安装过程、测试及性能。
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
