


原标题:西北工业大学教授张雯:空间主动噪声控制如何实现?| CCF-GAIR 2020
2020 年 8 月 7 日-9 日,2020 全球人工智能和机器人峰会(CCF-GAIR 2020)于深圳举行。
CCF-GAIR 2020 峰会是由中国计算机学会(CCF)主办,雷锋网、香港中文大学(深圳)联合承办,鹏城实验室、深圳市人工智能与机器人研究院协办的全球盛会。大会主题从 2016 年的学产结合,2017 年的产业落地,2018 年的垂直细分,2019 年的人工智能 40 周年,秉承打造国内人工智能和机器人领域规模最大、规格最高、跨界最广的学术、工业和投资领域盛会。
8 月 8 日上午,在前沿语音技术专场中,西北工业大学智能声学与临境通信研究中心教授张雯首先带来了题为《开放空间声场主动控制技术》的主题演讲。

演讲一开始,张雯教授就指出,智能语音交互产品应用领域广泛,基于扬声器阵列的开放空间声场重构与控制应用前景广阔。
以此为背景,张雯教授主要从空间声场重构、空间多区域声场控制以及空间主动噪声场控制三方面介绍了开放空间声场主动控制技术。
空间声场重构方面,张雯教授先是提到了两种技术:
1. 基于惠更斯原理的波场合成 WFS,这种技术早期比较受关注;
2. 近期更受欢迎的是 Ambisonics 面向场景的编解码技术,这一技术以声波辐射模态为基地函数对声场建模,通过处理经波域转换后的 Amibisonic 信号实现声场重构与控制。
随后,张雯教授谈到了空间声场重构的另一方面——前端声场处理。实际上,前端声场处理也有两个方面,一是宽带信号的重构,二是对播放环境的补偿。在此,张雯教授通过客厅的例子进行了详细解释。
空间多区域声场控制方面,张雯教授也介绍了两种方法——声学对比度法(最大化由扬声器阵列产生的暗区和亮区的声学差异)和声压匹配法(保证亮区的能量足够大时,还要产生期望的声场)。
张雯教授表示,多区域声场技术相对灵活、自由度高、可设计性强,但同时复杂性也很高。因此,对这一技术进行系统评价是一个关键:
我们提出了一种对这一系统的可实现性进行评价的理论,基于声区的位置以及亮区期望重构声场的信号来得到可实现性系数,越接近 1 实现性越高,越接近 0 表示可实现性越低。
在此基础之上,张雯教授引出了报告的第三部分——空间主动噪声控制。
据张雯教授介绍,主动噪声控制于上世纪 40 年代被发明,是当前最为有效的控制低频噪声的手段,其基本原理是以声消声。
实际上,与我们的日常生活最贴近的主动噪声控制案例就包括降噪耳机和汽车场景中的降噪。张雯教授也表示,目前很多汽车厂商都在开发主动噪声控制,其中最为成熟的是对引擎噪声的控制,原因在于声学传感器和振动传感器的结合。
通过对汽车降噪案例的详细解释,张雯教授认为:
区域内的主动噪声控制就是结合麦克风阵列、扬声器阵列以及声场控制技术实现三维空间区域内的降噪效果。
演讲最后,张雯教授从两个方面提到了最新的工作考量——传声器新设计和结合 AI 与分布式声学的信号处理。
张雯教授总结称,在信号处理上要关注的是语音信号和噪声信号的宽带随机性质,特别是对中高频和快速变化信号的跟踪能力,在这些情况下声场控制的难度急剧增加,还将有大量的工作待展开。
以下为西北工业大学智能声学与临境通信研究中心教授张雯的全部演讲内容,雷锋网作了不改变原意的整理及编辑:
各位嘉宾早上好!非常高兴今天能在这里和大家分享一些我们近期的工作,我今天报告的主题是开放空间声场主动控制技术。
众所周知,当下智能语音交互产品形态众多,数目呈指数增长,应用领域非常广泛,产品线涉及到手机终端、智能可穿戴设备、智能音响、智能大屏、智能家居以及车载环境内的导航交互等等。实际的语音交互环境是非常复杂的,比如说声源可能处于近场或是远场,同一环境下可能存在多个声源,有干扰、噪声和混响等等。
在前端处理方面,目前采用麦克风阵列和扬声器阵列相结合的多通道语音通信系统,这是一种被广泛采用的智能语音交互方案。接收端,我们通常采用麦克风阵列进行远场识音和前端的语音增强。同样,在声音的播放端,也有越来越多的产品采用多个扬声器,也就是扬声器阵列进行真实自然的声场回放。它的主要目的在于,一方面增强语音的音效,另一方面添加空间声的听感。
这种多通道的语音通信系统被应用于各种应用,比如说会议系统、车载通信以及一些新兴的产品,比如说智能音响、智能大屏等等,这样的系统希望给用户提供两方面极致的体验,一方面是解放用户的双手,实现免提通信;另一方面想给用户提供身临其境的通信感。
今天的报告主要是关注声音的播放端,也就是基于扬声器阵列的开放空间声场控制,它有着非常广泛的应用前景。
大家最熟悉的就是家庭影院场景,客厅里可以使用多个扬声器来构建环绕的音效感,我们甚至可以重放录制的场景,比如说音乐厅、演播厅等。随着技术的不断发展,我们在这个领域开始有了一些新的尝试,比如说可以用一个扬声器阵列在开放空间控制多个区域的声场,我们将其叫做多区域声场控制,或是开放空间下形成的个人声区,这是没有任何障碍物的。
我们这里展示的是一个在开放的办公室里,用一个阵列同时控制三个区域。这样的技术可以用于各种开放共享的环境,比如说开放办公室、展会大厅以及车载环境。
车载环境是一个非常典型的复杂声场,首先用户自己在播放声音,其次汽车在行驶的过程中也会遇到各种各样的噪声,因此我们要对噪声进行抑制,目的就是在驾驶员和乘客的头部位置构建自己的声区。
基于声场控制我们还有一些新的应用,比如说智能家居的噪声控制,也就是说,基于声场控制我们可以抑制噪声向外的辐射。其应用场景比如厨房中的抽油烟机。
今天的报告主要有三个部分,将从最简单、成熟的单区域声场重构技术展开。
单区域声场重构,顾名思义就是在空间的一个区域内控制声场。声场是声波在空间形成的,可以用波动方程进行描述和建模,比如一个区域内声压和空间表述决定,所以我们只要通过控制这些量,就可以实现一个区域里的声场重构。通常在这个技术中,我们忽略了倾听者本身的身体反射。
这个领域的两个比较重要的技术,一是 WFS 波场合成,二是 Ambisonics 技术。这两项技术的基本原理都是对区域内的声场进行建模,然后通过模型来控制产生的声场。
具体来讲,波场合成是基于惠更斯原理。点声源产生的波震面可以看成是很多次级声源组成的,次级声源产生的波阵面之和在每个时刻都等同于初始的声波,产生声波的波速和频率与原始声波是完全相同的,这就是基础的建模思路。所以我们只要把扬声器阵列放在波震面上,同时让扬声器阵列的输出信号等同于次级声源的信号,从而形成虚拟声源,产生音效。
这个技术听上去比较简单,事实上在执行过程中有一些限制,一方面需要波阵列的结构,另一方面需要知道每一点刺激声源的信号,同时在具体实施中通常都要通过构建大型的扬声器阵列来实现。
这个技术在早期比较受关注,近期更为受到欢迎的是 Ambisonics 技术,Ambisonics 用波动方程的基本解来对声场进行建模,基本解有两部分,一是随角度变化的球形函数,同时球形函数在球面上是一组正交基,另外一个是球贝塞尔函数。最终是把一个声场转为一组系数,重构系数就可以进行声场重构,同样的道理,可以通过控制系数来控制一个区域内的声场,这是一些基本原理。
所以单区域声场重构就是物理意义上的准确重构声场,一方面是发声单元扬声器的布置,包括扬声器作为个体的设计以及多个扬声器作为一个阵列的设计,我们这里展示的是实验室构建的大型扬声器阵列,包括代尔夫特理工大学构建的 128 通道的 WFS 系统和柏林工业大学构建的一个 832 通道的 WFS 系统。可以看到,WFS 系统通常都是基于大型扬声器阵列的,早期都是在实验室实现的。
目前,Ambisonics 系数已经被写到最新的空间声的音效中,可以通过非常好的数学理论实现,近年来受到了追捧。我们这里展示的是澳洲国立大学搭建的 32 通道的高阶 Ambisonics 系统,以及我们学校搭建的 64 通道的高阶 Ambisonics 系统。
空间声场重构的另一方面就是前端声场处理,同样也有两个方面。
一是我们重构的是宽带的语音信号,所以我们处理的是宽带信号的重构,这方面很多公司已经做了很多的基础研究,已经做得很好了。
另一方面我们要考虑重构环境的影响,比如说我们以客厅为例。在房间内构建家庭影院,房间本身是有混响的,而且混响有一定的声学特性,会导致重构性有所下降。如果我们需要对重构性进行补偿的话,将是比较复杂的处理系统,目前大多数商业系统都没有考虑对播放环境的补偿。
所以我们在实验室针对重构环境的混响和时变声学特性,提出了多域的自适应信号处理,跟踪房间的声学系统的变化,并进行主动补偿。
我们在此展示的是补偿前和补偿后的效果图。
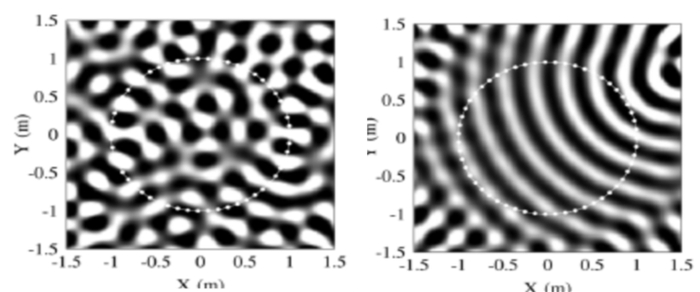
我们这里希望在白色圆线包围的区域里产生由虚拟源产生的声波,这里画的是波震面,四个轴代表房间的四面墙。如果不对它进行任何处理的话,房间早期的反射和混响就会使得我们重构的声场远离目标声场,所以我们要实时跟踪环境并进行补偿。
接下来更为动态的展示是带有主动房间补偿的空间声场重构,这里展示的是杜比 5.1 和基于扬声器阵列的系统。

杜比 5.1是 5 个白圈展示的扬声器位置,白色区域是控制区,我们希望产生来自于某个虚拟源对应的声波,只有这个来路方向会进入到控制区域,而其他的早期反射把它补偿掉。所以扬声器放了两个信号,一个是要产生期望声场,另外一个是要主动补偿到房间环境。
基于扬声器阵列也是一样的道理,通过增加扬声器的数量可以实现更为精准的控制,比如这里产生的不是点声源而是平面波,其他早期的反射和混响会被主动补偿掉。
在这个基础上,我们首次提出了空间多区域声场控制技术,也就是用一个扬声器阵列同时控制多个区域的声场。典型的应用包括在各种公共环境下产生个人声区,以及在嘈杂的环境下产生静区。
同样有两个示例,这里第一个示例是可以在两个声区产生两个独立的声场。
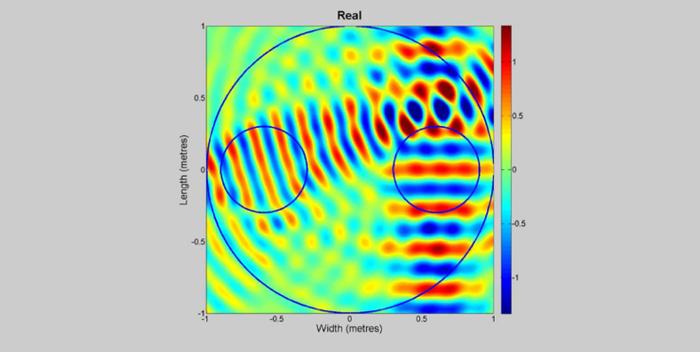
外面的黑圈是扬声器阵列,中间两个小圈是想产生声场的两个区域。两个声波来自于不同的方向,是相互独立的。
二是由一个扬声器阵列产生的两种声区。
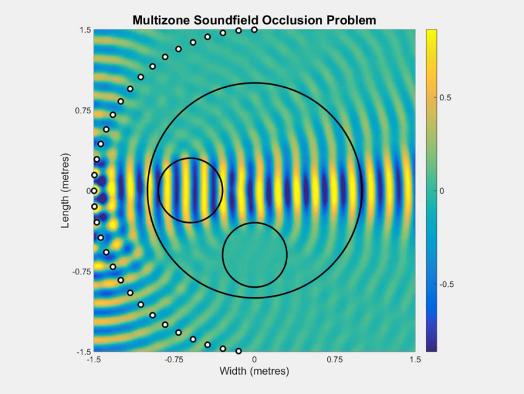
产生的两个区域中,一个是亮区,能量比较大;一个是暗区,能量比较小,我们也称之为静区。在暗区内有一个用户,可以实时移动麦克风,我们可以实时跟踪他,产生安静的区域。
所以多区声场控制也有两种方法。一是声学对比度法,也就是最大化暗区和亮区的声学差异。另外一个是声压匹配法,即在保证亮区的能量足够大时,还希望产生期望的声场。
多区域声场技术相对比较灵活、自由度很高、可设计性很强,但同时复杂性也很高。所以我们在这个方面的研究,除了提出技术本身的应用场景,我们还提出是否可以对这个技术进行系统评价。
我们提出了一种怎样对这一系统的可实现性进行评价的理论,基于声区的位置以及亮区期望重构声场的信号来得到可实现性系数(在 0 和 1 之间),越接近 1 实现性越高,越接近 0 表示可实现性越低。
比方说,两个声区中,亮区重构声波的来波方向跟两个声区的连线方向是垂直的,这种情况下它的可实现性比较强。如果声波的来波方向和两个方向是一致的,不可避免的结果便是两个声区之间有相互的干扰,可实现性也就会比较低。实际上我们现在举的例子比较简单,这个理论可以应用于各种场景。
同时,我们在实验室还构建了多区域声场控制的初步演示系统。
基于此,如果我们能控制一个区域内的多声场,可以在嘈杂环境中产生一个安静的区域,那么我们是否可以做一些在开放空间的主动噪声控制技术,也就是在一个区域内进行主动噪声控制。
到目前为止,主动噪声控制是最为有效的控制低频噪声的手段,基本原理是以声消声。
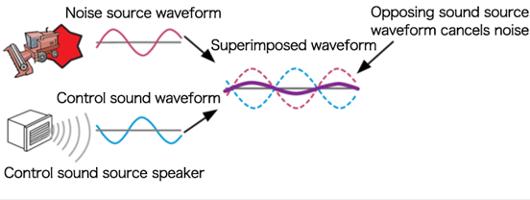
也就是说,我们有一个主噪声源,同时有一个次级声源,扬声器在两个声波叠加的时候可以达到噪声抑制的目的。主动噪声控制是上个世纪 40 年代发明的,目前已经成功应用于一些产品中,其中大家最为熟知的就是降噪耳机。
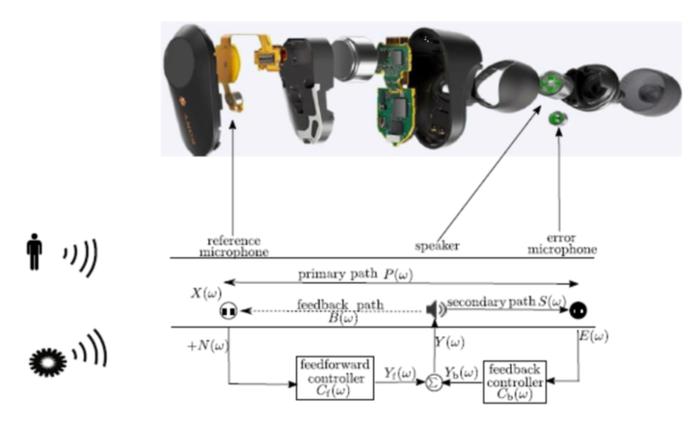
降噪耳机的结构通常是,耳机外面是参考麦克风,用来收录主噪声的参考信号;靠近耳朵一端会布置次级声源和误差麦克风,误差麦克风是我们的控制点。如果误差麦克风达到降噪效果,进入耳朵的能量就非常小,耳机就可以达到降噪的目的。
这一系统同时还涉及到前馈控制和反馈控制,利用参考麦克风信号和误差麦克风信号控制次级声源发出的次级噪声。
可见,其原理是比较简单的,但在具体执行过程中主要的难点和痛点就是噪声的特性。噪声具有宽带非平稳和快速变化的特性,次级声源和误差麦克风离得很近,离我们的耳朵也很近,所以整个系统的处理时间非常少,我们对系统的实时性要求非常高,也是整个系统最大的难点问题。
商业应用中,我们已经看到很多成功的降噪耳机。目前科研界和企业界关注的另一个点是能否可以把这个技术应用到开放空间的主动噪声控制,一个典型应用场景就是汽车。
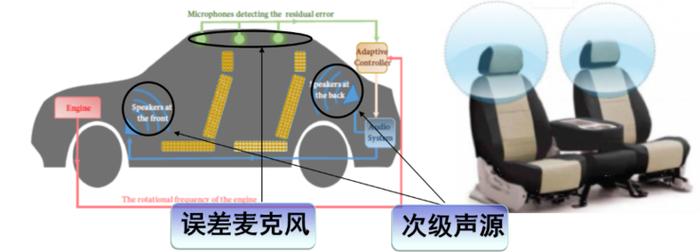
汽车在行驶过程中有各种各样的噪声,包括路噪、胎噪、风噪、引擎噪声等。所以目前很多的车商都在开发汽车座舱的主动噪声控制,相对而言比较成熟的就是对引擎噪声的控制。
它的基本原理是,在离驾驶员和乘客头部比较近的区域布置一些麦克风阵列,比如误差麦克风。我们要在这些点上进行控制,离用户比较近,用户听到的声音也就比较小。比如说在汽车的车顶或座位上,用汽车自带的播放系统播放次级噪声。
之所以引擎噪声比较容易控制,是因为可以结合声学传感器和振动传感器。振动传感器可以放在引擎端监测噪声,可以提前获取一些主噪声的参考来设计系统。而其他噪声,比如路噪、风噪、胎噪更加宽带,变化更加快且具有中高频的特点,目前只能用一些声学传感器进行监测。
区域内的主动噪声控制就是结合麦克风阵列、扬声器阵列以及声场控制技术实现三维空间区域内的降噪效果。
这里有一个展示,最外圈的蓝线是扬声器阵列,红线所包围的区域就是控制区域。我们可以在这个区域的便捷来布置一些麦克风。这里画的是波震面,黑色和白色分别代表幅度正一和负一。
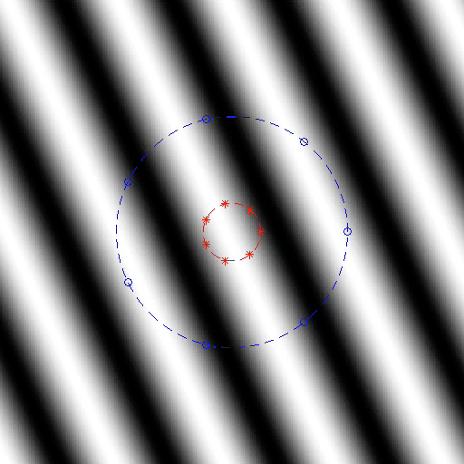
整个系统收敛之后,中间区域的幅度会比较小,接近于零。
我们实际上也完成了车内实测数据的验证。我们用球形麦克风阵列放在乘客头部位置收录一些噪声,包括引擎的噪声、空调噪声以及不同路况的噪声,并在实验室对这些噪声进行分析,得到所需的降噪信号。
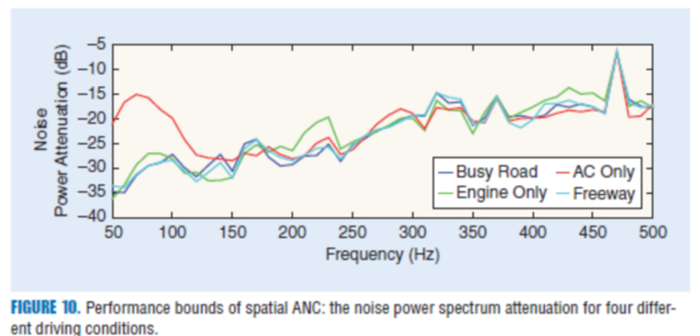
我们把得到的信号再从车载的系统中放出来,在一个环境下测试我们的降噪效果,基本 500 赫兹以下可以实现 15-20 dB 的降噪效果。
基于同样的原理,我们是否可以基于声场控制,来控制噪声向外的辐射?这里有一个展示。
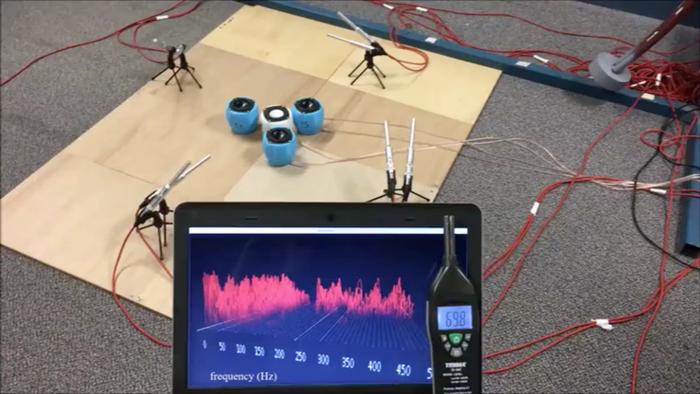
中间白色的扬声器是我们的主噪声,外面三个蓝的扬声器是次级噪声。主噪声是三个协作声量,环境内的声量达到了 78 分贝。外面一圈是误差麦克风,我们可以基于麦克风的数据进行控制。
次级噪声发出反噪声信号之后,把主噪声分量进行一致,整个环境中的主噪声就降低到了 68 分贝。我们再把次级噪声放回去,可以达到相同的降噪量,大概 68 分贝。
这是一个自适应的系统,是很简单的展示,主要是在考量未来是否可以控制智能家居向外辐射的噪声。
总体来说,开放空间声场控制有广阔的应用场景,但目前存在很多的难点。
一方面,计算复杂度随着次级声源数目和传感器数目的增加而急剧增加;同时,开放空间声场控制,特别是噪声控制对实时性的要求比较高;为了达到精准的效果还要做在线的声学路径估计,会进一步增加系统的复杂度;最为关键的痛点问题是宽带非平稳噪声和中高频信号的追踪能力。
在这一方面我们也有一些最新的工作、最新的考量,依然是从两个方面出发:一是传声器阵列设计,二是前端信号处理。
在传声器设计当中,我们提出了一种新的扬声器的设计方法,即指向性扬声器。传统的信号处理通常把扬声器建模为 3D 空间的点声源,具有全指向性的辐射特性。这种辐射具有不可控性,整个系统的复杂度比较大,要用多个传声器才能达到同样的效果。
所以我们在想,是否可以构建一个具有可变指向性的传声器,多个扬声器放在一个系统上,可以控制向外空间的指向性,甚至可以控制阵列内部和外部声场进而有效抑制混响,相当于在发声端做了波束形成技术。
那么该怎样做联合优化?比如说有多个阵列,我们希望其内部实现特定的声场,同时向外辐射尽可能小,小到不会引起混响,我们就不用考虑播放环境对系统的影响,也就不需要再做一些在线的声学估计了。
在信号处理方面,我们也有一些最新的尝试,比如说结合 AI 做基于 Deep ANC 的非线性主动噪声控制,我们也可以学习一些噪声的特性,这样我们可以使整个系统具有更快的收敛能力和更强的噪声跟踪能力。
另外一个工作是基于分布式的声场控制,基本原理是把一个大型的多通道系统拆分成多个小型系统,这样的话我们就可以降低整个系统的运载负荷、提高系统跟踪噪声的能力,但弊端是收敛性有所减慢。
总体上看,开放空间声场控制是使用多个扬声器控制一个区域或是多个区域的声场,具有可设计性强、成本低、灵活性高的特点,有广阔的应用场景和市场空间。主要针对的是大区域、多区域混响环境下的声场控制,这个情况下有两方面,一个是传声器、传感器阵列的新设计本身起了非常重要的作用。信号处理方面,我们需要关注的是语音信号和噪声信号的宽带随机性质,特别是中高频信号和快速变化信号的跟踪能力。在这种情况下整个声场控制的难度是急剧增加的,我们在尝试结合人工智能、分布式处理的工作,还有大量的工作有待展开,感谢大家的聆听。
雷锋网雷锋网雷锋网(公众号:雷锋网)
雷锋网原创文章,未经授权禁止转载。详情见转载须知。
