


时隔三年,英伟达最强芯片 Tesla V100 有了继任者,20 倍的性能提升着实让人有些招架不住。
虽然因为新冠疫情爆发,今年的 GTC 2020 大会也在最后时刻宣布转为线上,不过人们期待 7 纳米制程英伟达 GPU 的热情并没有消退。
英伟达当然理解我们的心情,在 GTC 正式开幕一天前,英伟达 CEO 黄仁勋提前放出了一段视频——在老黄美国加州 Los Altos Hills 的家中,全球最大的 GPU 正式「出炉」了:

我们说的这个「出炉」,它可真是字面意思。
事实上,黄仁勋今年的整个 GTC 大会的主 Keynote 环节都是在这个烤炉前进行的。他还表示,这是英伟达有史以来第一个「厨房 Keynote」。

和普通家庭一样,黄老板家的厨房里也摆着「煤气灶」,显得朴实无华且枯燥。
黄老板展示的安培(Ampere)架构 GPU 系统以最新英伟达 Tesla A100 芯片组成,被认为是迄今为止 GPU 算力最大的一步提升。
A100:面积最大,性能最强
具体提升了多少?还记得三年前推出、至今仍然业界领先的 Volta 架构芯片 Tesla V100 吗?V100 用 300W 功率提供了 7.8TFLOPS 的推断算力,有 210 亿个晶体管,但 A100 的算力直接是前者的 20 倍。
「A100 是迄今为止人类制造出的最大 7 纳米制程芯片,」黄仁勋说道。A100 采用目前最先进的台积电(TSMC)7 纳米工艺,拥有 540 亿个晶体管,它是一块 3D 堆叠芯片,面积高达 826mm^2,GPU 的最大功率达到了 400W。
这块 GPU 上搭载了容量 40G 的三星 HBM2 显存(比 DDR5 速度还快得多,就是很贵),第三代 Tensor Core。同时它的并联效率也有了巨大提升,其采用带宽 600GB/s 的新版 NVLink,几乎达到了 10 倍 PCIE 互联速度。

随着安培架构出现的三代 Tensor Core 对稀疏张量运算进行了特别加速:执行速度提高了一倍,也支持 TF32、FP16、BFLOAT16、INT8 和 INT4 等精度的加速——系统会自动将数据转为 TF32 格式加速运算,现在你无需修改任何代码量化了,直接自动训练即可。
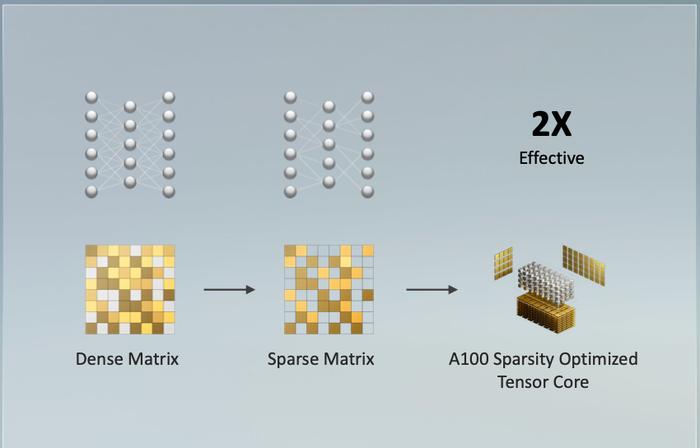
A100 也针对云服务的虚拟化进行了升级,因为全新的 multi-instance GPU 机制,在模拟实例时,每块 GPU 的吞吐量增加了 7 倍。
最终在跑 AI 模型时,如果用 PyTorch 框架,相比上一代 V100 芯片,A100 在 BERT 模型的训练上性能提升 6 倍,BERT 推断时性能提升 7 倍。
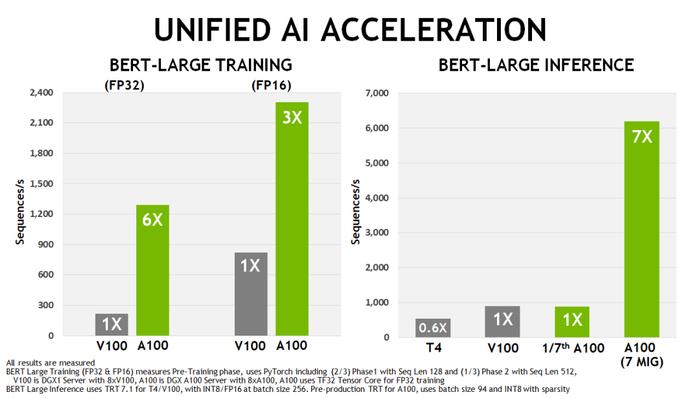
图 2. 相比 Tesla V100 和 Tesla T4,A100 GPU 在 BERT 训练和推理上的性能
「放弃 CPU」的超级计算机
芯片能力的提升,是为了追上今天 AI 算力需求的爆炸性增长。在英伟达看来,自 2017 年 5 月 Volta 架构的 Tesla V100 推出后,今天人们对于 AI 模型训练算力的需求竟增长了 3000 倍(从当年的 ResNet 发展到今天的 Megatron-BERT 等算法)。
看来制程、架构上的提升还是不够。另一方面,对于云服务厂商来说,人们用算力来做的事总在不断变化,所以也难以设计专有优化的芯片架构。如何寻找一种可以适应更多应用方向的设计方案呢?
三年前英伟达设计 Volta 芯片时已经思考了这一问题。今天推出的安培架构除了性能提升 20 倍,还可以实现 1-50 倍的扩展。英伟达的体系不仅可以向更多 GPU 扩展(Scale-Up),还可以向外扩展(Scale-Out)以满足人们永无止境的算力需求。
今天的人工智能任务包括模型的训练和推断,在原有人工智能系统 DGX-1 中,我们还在使用 GPU 负责训练、CPU 负责推断的分工方式。而有了 A100 芯片加持,第三代 DGX 可以把训练与推断全部交给 GPU 来完成,充分发挥先进架构的加速能力。
这就是黄仁勋「刚刚出货」第三代 DGX:

这代 DGX A100 单节点包含 8 块 GPU,可以输出 5PetaFLOPS 的 FP16 算力(比 TFLOPS 又多了三个零,10 的 15 次方),今天就已开卖,售价 19.9 万美元。该价格和上一代 DGX-2 基本持平(DGX-2 首发价 39.9 万美元,但内含 16 块 V100 GPU)。首批 OEM 厂商包括浪潮、联想、惠普,上线的云服务公司覆盖 AWS、微软、谷歌、阿里巴巴、腾讯、百度…… 大厂几乎全都覆盖了。

这是世界上最大的 GPU,重 50 磅(约合 22.7 千克,相当于一个六七岁孩子的体重)。
A100 使用了成本很高的新制程、新内存,使用起来效果如何?英伟达算了一笔账:今天的数据中心假如使用 50 个 DGX-1 系统(基于 Tesla P100)用于 AI 算法的训练,600 个 CPU 用于推断,硬件成本是 1100 万美元,需要使用 25 个服务器机架,消耗 630kW 功率。
使用最新的 DGX A100,我们只需要并联 5 个 DGX A100 系统,GPU 同时用于 AI 训练和推断,成本 100 万美元,1 个机架,使用 28kW 功率。
「现在,你只需要十分之一的硬件成本,二十分之一电力消耗就能做同样的事。The more you buy, the more you save !」黄仁勋说道。

「The more you buy, the more you save」,语音请自行脑补(话说黄老板不考虑注册个音频商标吗?)。
英伟达还宣布了 DGX A100 SuperPOD,面向更大的云服务算力需求。它可以支持 140 个 DGX A100 系统(内含 1120 块 A100),可通过 170 个 Mellanox Quantum 200G infiniBand 切换,实现 700PFLOPS 的 AI 算力。这样一组服务器三周之内就可以建成。
英伟达自用的超级计算机「土星五号」,一直被用于医疗影像、自动驾驶任务的训练,原版搭载 1800 个 DGX 系统,输出 1.8ExaFLOPS 算力,现在加挂了四个 SuperPOD,最终可以实现 4.6ExaFLOPS 算力,成为了世界最强劲的超级计算机之一。

在今日的发布会上,英伟达也发布了 HGX A100,在性能上,凭借第三代 Tensor Core,HGX A100 在 TF 32 精度上将 AI 负载的处理速度提高了 20 倍,而 FP64 精度的高性能计算速度提高了 2.5 倍。其中,HGX A100 4-GPU 可为最苛刻的 HPC 工作负载提供近 80 teraFLOPS 的 FP64 算力。HGX A100 8-GPU 版可提供 5 petaFLOPS 的 FP16 深度学习算力,而 16-GPU 的 HGX A100 提供惊人的 10 petaFLOPS,为 AI 和 HPC 创建了当前世界上最强大的加速扩展服务器平台。
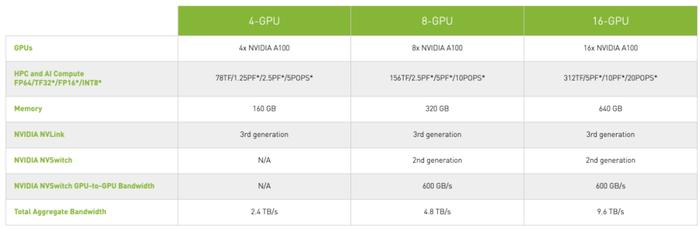
HGX A100 的特性。
如今,AI 应用已在语音、推荐系统、智能医疗、自动驾驶等任务上得到了实践。除了算法技术的发展,人们对于算力的需求也有着疯狂的增长。英伟达已不再把自己定义为芯片制造商,而是一家「数据中心扩展公司」(Data center scale company),这也指明了它未来重点的发展方向。
「在未来,人们使用的计算单元将会是整个数据中心。其背后不是数个 CPU,而会是并联计算的 GPU 阵列。数据中心需要承载大量不同的计算任务,它们有不同的需求。我们需要训练、推断、科学计算、云游戏都能做的硬件,并对这些计算都进行加速,」黄仁勋说道。
这或许就是 GPU 的不可替代之处。
终端、自动驾驶全覆盖
安培架构如此强大,英伟达这次也没有让数据中心以外的应用方向多等,直接放出了同样使用新架构的端侧芯片 Nvidia EGX A100。

英伟达还介绍了旗下最新技术的一些应用案例,其中包括 4 月底刚刚发布的小鹏汽车 P7,以及宝马集团采用英伟达解决方案全面提升工厂物流管理水平的例子。小鹏 P7 的 XPILOT 3.0 是国内首个搭载英伟达 Xavier 计算平台的自动驾驶量产方案,而且还搭载了两套(硬件互相独立,互为冗余)。

在软件方面,英伟达推出了自己的语音交互框架 Jarvis,Apache Spark 3.0 现在推出了针对英伟达 GPU 的机器学习支持。英伟达今日也更新了与 GPU 相匹配的软件 CUDA 11,以支持最新的 Ampere GPU 架构、多实例 GPU(MIG)分区功能,并为任务图、异步数据移动、细粒度同步和 L2 缓存驻留控制编程并提供 API。
英伟达还发布了深度学习超级采样技术 DLSS 2.0 版,可以使用 540p 的原画面渲染出 1080p 的效果。「神经网络现在可以『脑补』出低画质像素没有表现出的光源,并通过前后帧的类似画面推测出当前帧应该出现的更多细节,」黄仁勋说道。「现在 DLSS 2.0 的效果甚至好于采用常规抗锯齿等技术渲染出来的高清晰度画面。」

GeForce RTX 3080 Ti 还远吗?
最后,很多人关心的问题可能是:消费级显卡 GeForce RTX 在哪里?
GTC 大会之前,曾有爆料说英伟达今年三季度将会发布安培架构的 GeForce RTX 30 系列显卡,其光追效果可以提升 4 倍,低端卡也可以秒杀当前版本的 RTX Titan,很多人都在期待 7 纳米的英伟达 GPU 在游戏上的表现。黄仁勋这次只是表示:「全新架构安培我们现在已经用在 DGX 上了,英伟达正在努力把新架构的芯片用在机器人、自动驾驶汽车等领域中。未来也会用在图形计算上。」

光线追踪技术非常诱人:这样的小游戏画面,是由一块 Quadro RTX 8000 实时渲染出来的。
黄仁勋的表达非常谨慎,不过至少英伟达在这次 GTC 上向我们展示了下一代光线追踪技术在《我的世界》等游戏中的效果,并将其标记为 RTX 30/20 系列专有:

我的世界中绝大多数建筑都是由玩家自行建造的,这里可没有什么可以「造假」的余地,一切都需要依靠 GPU 和新技术进行实时渲染。

看来距离 7 纳米制程的 Geforce 3080Ti 出世也已不远了,等等党永远不输。
