


原标题:ELECTRA中文预训练模型开源,仅1/10参数量,性能依旧媲美BERT

在去年11月份,NLP大神Manning联合谷歌做的ELECTRA一经发布,迅速火爆整个NLP圈,其中ELECTRA-small模型参数量仅为 BERT-base模型的1/10,性能却依然能与BERT、RoBERTa等模型相媲美。
在前不久,谷歌终于开源了ELECTRA,并发布了预训练模型,这对于缺大算力的高校和企业,简直是一大福音。
然而,其发布的预训练模型只是针对英语,却非如BERT那样是多语言版本。对于其他语言(例如中文)的研究者来说,则非常遗憾。

(雷锋网)
针对这一问题,今天哈工大讯飞联合实验室(HFL)基于ELECTRA开源代码,发布了中文版的 ELECTRA 预训练模型。
ELECTRA

(雷锋网)
ELECTRA预训练模型的作者是斯坦福SAIL实验室Manning组和谷歌大脑研究团队,初次出现是在2019年北京智源大会上面。作为一种新的文本预训练模型,ELECTRA 新颖的设计思路、更少的计算资源消耗和更少的参数,迅速引起了大批关注者。特别是在去年 11 月 ICLR 2020 论文接收出炉后,曾引起NLP圈内不小的轰动。

(雷锋网(公众号:雷锋网))
论文链接:https://openreview.net/forum?id=r1xMH1BtvB
论文中这张图能够说明一切问题:
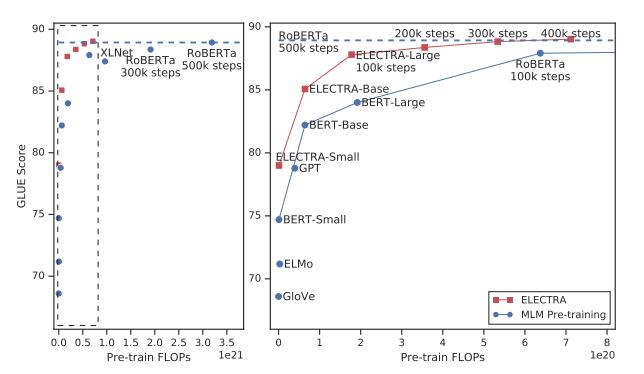
图注:右图是左图放大的结果。
如上图所示,ELECTRA模型能够在训练步长更少的前提下得到了比其他预训练模型更好的效果。同样,在模型大小、数据和计算相同的情况下,ELECTRA的性能明显优于基于MLM的方法,如BERT和XLNet。
所以,ELECTRA 与现有的生成式的语言表示学习方法相比,前者具有更高的计算效率和更少的参数(ELECTRA-small的参数量仅为BERT-base的 1/10)。
ELECTRA能够取得如此优异结果,基于其新颖的预训练框架,其中包含两个部分:Generator和Discriminator。
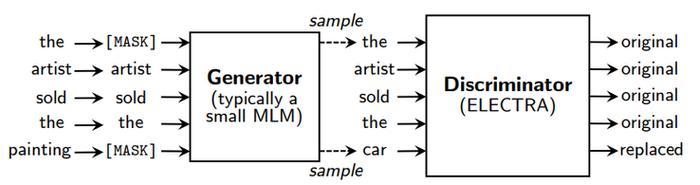 Generator: 一个小的MLM,在[MASK]的位置预测原来的词。Generator将用来把输入文本做部分词的替换。Discriminator: 判断输入句子中的每个词是否被替换,即使用Replaced Token Detection (RTD)预训练任务,取代了BERT原始的Masked Language Model (MLM)。需要注意的是这里并没有使用Next Sentence Prediction (NSP)任务。
Generator: 一个小的MLM,在[MASK]的位置预测原来的词。Generator将用来把输入文本做部分词的替换。Discriminator: 判断输入句子中的每个词是否被替换,即使用Replaced Token Detection (RTD)预训练任务,取代了BERT原始的Masked Language Model (MLM)。需要注意的是这里并没有使用Next Sentence Prediction (NSP)任务。在预训练阶段结束之后,只使用Discriminator作为下游任务精调的基模型。
换句话说,作者们把CV领域的GAN运用到了自然语言处理。
值得注意的是,尽管与GAN的训练目标相似,但仍存在一些关键差异。首先,如果生成器碰巧生成了正确的token,则该token被视为“真实”而不是“伪造”;所以模型能够适度改善下游任务的结果。更重要的是,生成器使用最大似然来训练,而不是通过对抗性训练来欺骗判别器。
中文ELECTRA预训练模型
目前已有的开源 ELECTRA 预训练模型只是英文的预训练模型。但世界上还有许多其他语言(例如中文)研究的学者,他们需要与其相应的语言预训练模型。
然而,谷歌官方除了BERT、RoBERTa等预训练模型有多语言版本外,其他例如XLNet、T5都没有相应的多语言版本,只有英文。其中原因在于相比于只在英语上做预训练,多语言的预训练需要收集相应语料,需要调配不同语言语料的比例等,比较麻烦。因此大概率上,ELECTRA 也不会出中文版或多语言版的预训练模型。
而另一方面,作为中文社区,我们国人自己对如何做中文的预训练则更为了解,我们自己来做相应的预训练可能会比谷歌官方来做会更好。
由哈工大讯飞联合实验室资深级研究员、研究主管崔一鸣所带领的团队之前曾做过系列类似的开源工作,即基于开源预训练代码,加上中文数据集来训练中文版预训练模型。例如中文版的系列BERT模型、中文版XLNet等,在GitHub上开源后反响不错,在许多中文评测任务中也曾有不少队伍使用他们开源的预训练模型进行改进。
 Generator: 一个小的MLM,在[MASK]的位置预测原来的词。Generator将用来把输入文本做部分词的替换。Discriminator: 判断输入句子中的每个词是否被替换,即使用Replaced Token Detection (RTD)预训练任务,取代了BERT原始的Masked Language Model (MLM)。需要注意的是这里并没有使用Next Sentence Prediction (NSP)任务。
Generator: 一个小的MLM,在[MASK]的位置预测原来的词。Generator将用来把输入文本做部分词的替换。Discriminator: 判断输入句子中的每个词是否被替换,即使用Replaced Token Detection (RTD)预训练任务,取代了BERT原始的Masked Language Model (MLM)。需要注意的是这里并没有使用Next Sentence Prediction (NSP)任务。在预训练阶段结束之后,只使用Discriminator作为下游任务精调的基模型。
换句话说,作者们把CV领域的GAN运用到了自然语言处理。
值得注意的是,尽管与GAN的训练目标相似,但仍存在一些关键差异。首先,如果生成器碰巧生成了正确的token,则该token被视为“真实”而不是“伪造”;所以模型能够适度改善下游任务的结果。更重要的是,生成器使用最大似然来训练,而不是通过对抗性训练来欺骗判别器。
中文ELECTRA预训练模型
目前已有的开源 ELECTRA 预训练模型只是英文的预训练模型。但世界上还有许多其他语言(例如中文)研究的学者,他们需要与其相应的语言预训练模型。
然而,谷歌官方除了BERT、RoBERTa等预训练模型有多语言版本外,其他例如XLNet、T5都没有相应的多语言版本,只有英文。其中原因在于相比于只在英语上做预训练,多语言的预训练需要收集相应语料,需要调配不同语言语料的比例等,比较麻烦。因此大概率上,ELECTRA 也不会出中文版或多语言版的预训练模型。
而另一方面,作为中文社区,我们国人自己对如何做中文的预训练则更为了解,我们自己来做相应的预训练可能会比谷歌官方来做会更好。
由哈工大讯飞联合实验室资深级研究员、研究主管崔一鸣所带领的团队之前曾做过系列类似的开源工作,即基于开源预训练代码,加上中文数据集来训练中文版预训练模型。例如中文版的系列BERT模型、中文版XLNet等,在GitHub上开源后反响不错,在许多中文评测任务中也曾有不少队伍使用他们开源的预训练模型进行改进。
开源地址:https://github.com/ymcui/Chinese-BERT-wwm
开源地址:https://github.com/ymcui/Chinese-XLNet
在谷歌开源ELECTRA之后,崔一鸣等人再次推出中文版 ELECTRA。
训练数据集,仍和之前训练BERT系列模型所用数据是一致的,主要来自大规模中文维基及通用文本(中文网页爬取和清洗),总token达到5.4B。词表方面沿用了谷歌原版BERT的WordPiece词表,包含21128个token。
在本次的开源中,崔一鸣等人只发布了ELECTRA-base 和ELECTRA-small 两个模型。据崔一鸣表示,large版本由于参数较多,超参设置比较困难,因此模型发布会相应延后。
已发布的两个版本各自训练了大约7天时间,由于small版本的参数仅为base版本的1/10,在训练中,崔一鸣等人将其batch调为1024(是base的4倍)。具体细节和超参如下(未提及的参数保持默认):ELECTRA-base:12层,隐层768,12个注意力头,学习率2e-4,batch256,最大长度512,训练1M步ELECTRA-small:12层,隐层256,4个注意力头,学习率5e-4,batch1024,最大长度512,训练1M步

ELECTRA-small 仅 46 M。
在效果上,崔一鸣等人将之与他们之前做的系列中文版预训练模型进行了效果对比。
对比模型包括:ELECTRA-small/base、BERT-base、BERT-wwm、BERT-wwm-ext、RoBERTa-wwm-ext、RBT3。
对比任务有六个:CMRC 2018 (Cui et al., 2019):篇章片段抽取型阅读理解(简体中文)
DRCD (Shao et al., 2018):篇章片段抽取型阅读理解(繁体中文)
XNLI (Conneau et al., 2018):自然语言推断(三分类)
ChnSentiCorp:情感分析(二分类)LCQMC (Liu et al., 2018):
句对匹配(二分类)BQ Corpus (Chen et al., 2018):
句对匹配(二分类)
在下游任务精调中,ELECTRA-small/base模型的学习率设为原论文默认的3e-4和1e-4。值得注意的是,这里的精调并没有针对任何任务进行参数精调。为了保证结果的可靠性,对于同一模型,他们使用不同随机种子训练10遍,汇报模型性能的最大值和平均值(括号内为平均值)。
效果如下:
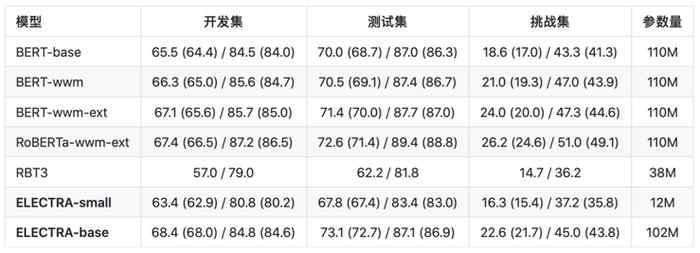
简体中文阅读理解:CMRC 2018(评价指标为:EM / F1)
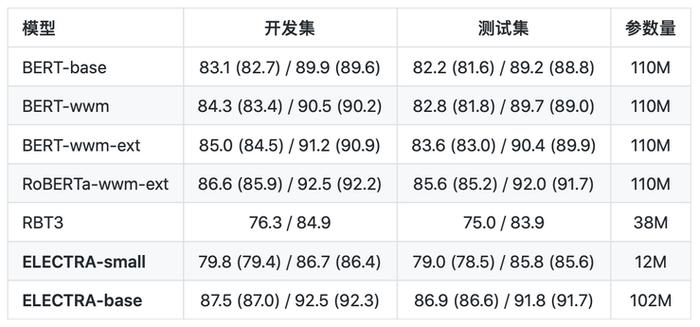
繁体中文阅读理解:DRCD(评价指标为:EM / F1)
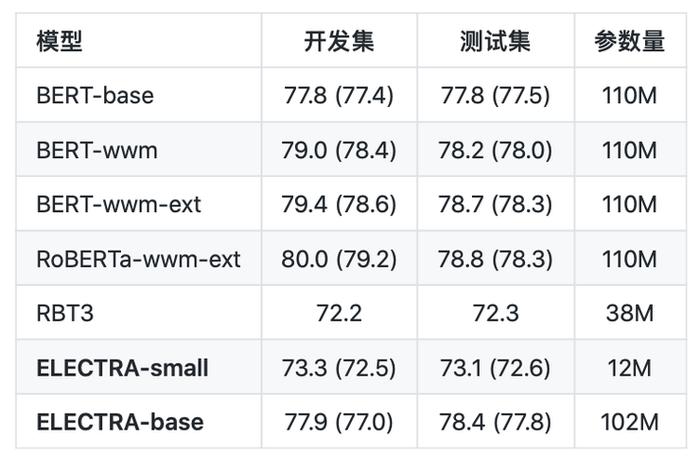
自然语言推断:XNLI(评价指标为:Accuracy)
情感分析:ChnSentiCorp(评价指标为:Accuracy)
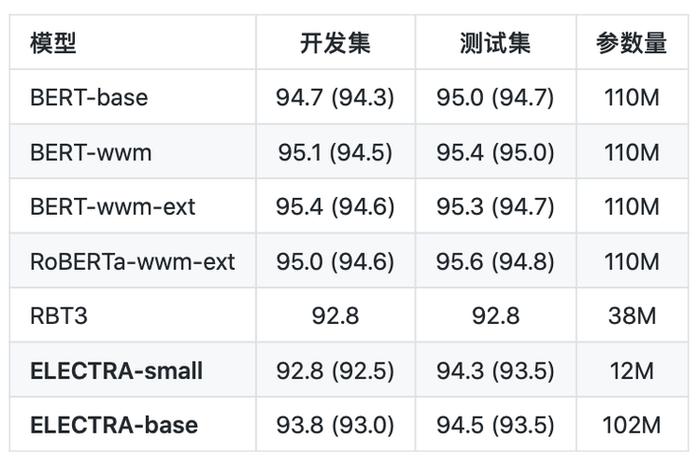
句对分类:LCQMC(评价指标为:Accuracy)
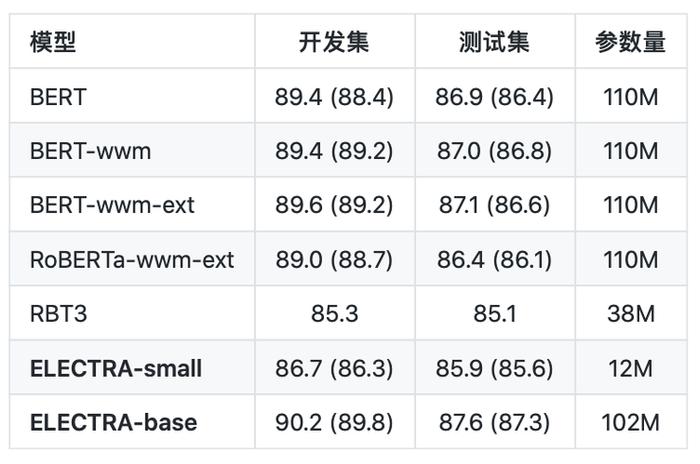
句对分类:BQ Corpus( 评价指标为:Accuracy)
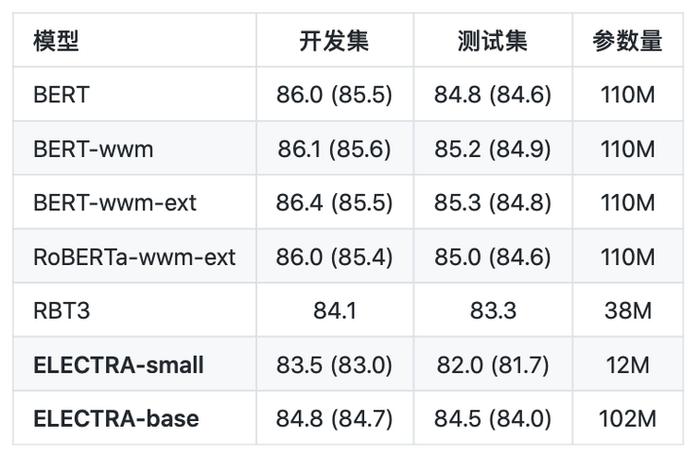 从以上的结果可以看出,对于ELECTRA-small模型,其效果在多数任务上显著超过3层RoBERTa效果(RBT3),甚至是接近BERT-base的效果,而在参数量上只有BERT-base模型的1/10。对于ELECTRA-base模型来说,在多数任务上超过了BERT-base甚至是RoBERTa-wwm-ext的效果。
从以上的结果可以看出,对于ELECTRA-small模型,其效果在多数任务上显著超过3层RoBERTa效果(RBT3),甚至是接近BERT-base的效果,而在参数量上只有BERT-base模型的1/10。对于ELECTRA-base模型来说,在多数任务上超过了BERT-base甚至是RoBERTa-wwm-ext的效果。其具体使用,可以查看Github项目:https://github.com/ymcui/Chinese-ELECTRA
雷锋网原创文章,未经授权禁止转载。详情见转载须知。
 从以上的结果可以看出,对于ELECTRA-small模型,其效果在多数任务上显著超过3层RoBERTa效果(RBT3),甚至是接近BERT-base的效果,而在参数量上只有BERT-base模型的1/10。对于ELECTRA-base模型来说,在多数任务上超过了BERT-base甚至是RoBERTa-wwm-ext的效果。
从以上的结果可以看出,对于ELECTRA-small模型,其效果在多数任务上显著超过3层RoBERTa效果(RBT3),甚至是接近BERT-base的效果,而在参数量上只有BERT-base模型的1/10。对于ELECTRA-base模型来说,在多数任务上超过了BERT-base甚至是RoBERTa-wwm-ext的效果。其具体使用,可以查看Github项目:https://github.com/ymcui/Chinese-ELECTRA
雷锋网原创文章,未经授权禁止转载。详情见转载须知。
