


原标题:代码也能预训练,微软&哈工大最新提出 CodeBERT 模型,支持自然-编程双语处理

近日,微软、哈工大在arxiv上联合发表了一篇论文,标题为《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》,再次拓宽了BERT的应用,将BERT应用到了Python、PHP、Java、JavaScript、Go、Ruby等编程语言的代码搜索和生成任务当中。

论文链接:https://arxiv.org/pdf/2002.08155.pdf
这篇论文提出了一个被称为「CodeBERT」的双模预训练模型,据作者介绍,这也是目前已知的第一个大型 NL-PL(自然语言-编程语言)预训练模型。
该预训练模型能够处理NL-PL 的普遍问题,例如用自然语言搜索代码、自动生成代码等。 所谓自然语言代码搜索,所要解决的问题是,如何通过自然语言query查找到所需的代码块,这和我们常用的搜索引擎(通过自然语言query来查找所需网页)类似。
事实上,微软Bing在2018年便上线了类似的功能,在搜索框中输入自然语言 “convert case using a function of R”,便会返回一段 R 代码。
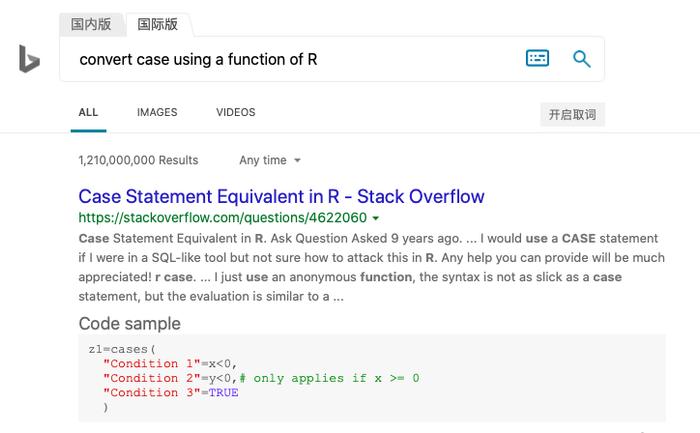
(雷锋网(公众号:雷锋网))
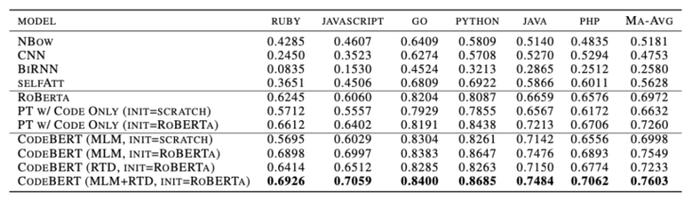
针对自然语言代码搜索,在这篇论文里,作者在 CodeSearchNet语料库上对CodeBERT进行了预训练并做微调,这是一个包含了 6 种较为普遍的代码语言(分别为Ruby、JavaScript、Go、Python、Java、PHP)的语料库。如下图所示,他们在自然语言代码搜索任务中取得了SOTA的结果:
而另一方面,代码文档生成任务,是未来能够极大节省程序员工作量的极具前景的一个研究方向。如下图所示,
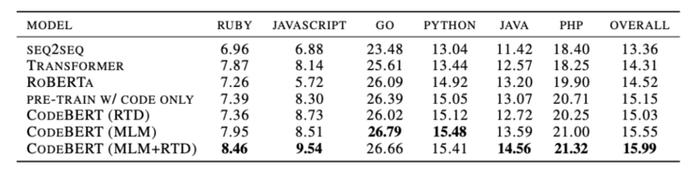
针对这个任务,CodeBERT也基本上都取得了SOTA结果,特别是相较于之前的ROBERTa模型,更是有显著的提高。 值一提的是,CodeBERT有一大亮点,即尽管它只在Ruby、JavaScript、Go、Python、Java、PHP等代码语言上进行了预训练,但预训练的模型却可以泛化到其他代码语言任务上,例如C#语言。
一、背景
BERT作为一种双向Transformer的编码器,其对预训练方法的创新深受业界和学术界的喜爱,虽然其他大规模的预训练模型例如ELMo、GPT等已经能够在各种NLP任务中提升SOTA。
但是上述提到的模型基本上都是面向自然语言处理,例如掩蔽语言建模、从未标记文本学习上下文表示。 相比以往的Bert的应用场景,作者另辟蹊径,推出双模态预训练模型,即兼顾NLP任务和Python、Java等编程语言。
具体来说,CodeBERT抓住了自然语言和编程语言之间的语义联系,能够支持自然语言代码搜索等NL-PL理解任务以及一系列像代码生成这样的生成任务。

(雷锋网)
一个NL-PL对,其中红线框中的是NL文本,黑色框是PL文本。 为了利用Nl-PL对的双模实例(bimodal instances)以及大量可用的单模代码(unimodal codes),作者使用了混合目标函数来训练CodeBERT,包括标准掩码语言建模和可替换Token检测。
在具体的训练过程,作者用了六种编程语言在多语言BERT的设置中训练模型。 我们首先来看下CodeBERT的模型框架。
二、框架
在模型的整体架构上,CodeBERT并未脱离BERT和Roberta的思想。和大多数工作类似,作者使用了多层双向Transformer。更为具体一点,作者使用的模型架构与Roberta-base完全相同,即都有12层,每层有12个自注意头,每个头的大小是64,隐藏尺寸为768,前馈层的内部隐藏尺寸为3072。
模型参数的总数为125M。 在预训练阶段,总共设计了两部分输入,一个是自然语言文本,另一个是编程语言的代码。对于自然语言文本将其视为单词序列,并拆分为WordPiece。对于编程代码,将其看做Token序列。 CodeBERT的输出也包括两个部分:1、聚合序列表示;2、有标记的上下文向量(contextual vector)。
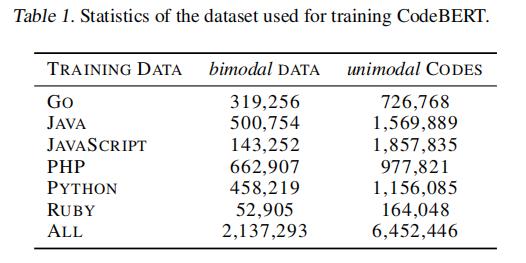
数据集统计 训练CodeBERT所使用的数据集是Husain等人在2019年提供的最新数据集,里面包括 2.1M双模数据和6.4M 单码数据,其中双模码数据是指自然语言-代码对的并行数据,单码是指“未成对”的数据。 另外一些数据来自开源Nonfork GitHub仓库。对这些数据的处理是采用了一些约束和规则进行过滤。
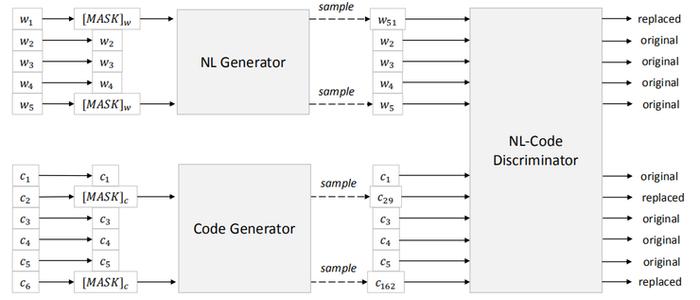
(雷锋网)
可替换Token检测目标图解 在模型训练的设计上,其主要包括两个目标,其一是掩码语言建模,其二是可替换Token检测。在第二个目标中,作者进一步使用了大量的单模码数据。
目标一:掩码语言建模。将NL-PL对作为输入,随机为NL和PL选择位置进行掩码,然后用特殊的掩码Token进行替换。注意,掩码语言建模的任务是预测出被掩码的原始Token。
目标二:替换Token检测。在这部分有两个数据生成器,分别是NL生成器和PL生成器,这两个生成器都用于随机掩码位置集(randomly masked positions)生成合理的备选方案。
另外,还有一个学习生成器用来检测一个词是否为原词,其背后原理是一个二进制分类器,这里与GAN不同的是,如果生成器碰巧产生正确的Token,则该Token的标签是“real”而不是“fake”。
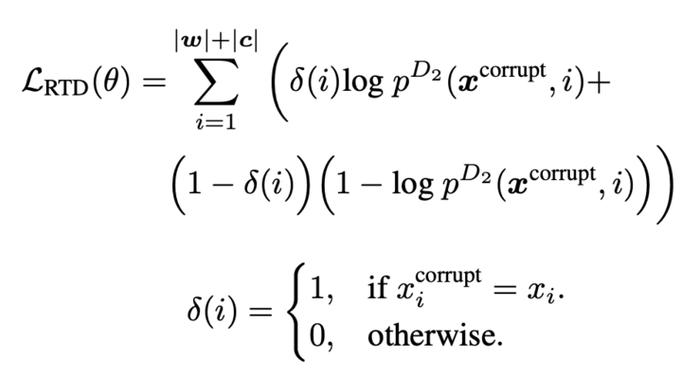
学习器的损失函数 经过调整后,损失函数优化如下:
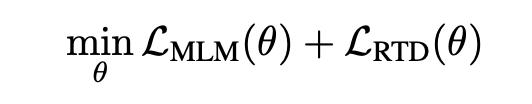
模型训练的最后一步是模型微调,具体操作是在NL-PL任务中使用不同的CodeBERT设置。例如在自然语言代码搜索中,会使用与预训练阶段相同的输入方式。而在代码到文本的生成中,使用编码器-解码器框架,并使用CodeBERT初始化生成模型的编码器。
三、实验
作者做了四个实验,分别是:1)将CodeBERT应用到自然语言代码搜索任务上,并与传统方法进行对比;2)进行NL-PL Probing实验,考察CodeBERT在预训练阶段到底学习了什么知识;3)将CodeBERT应用到生成任务当中;4)考察CodeBERT预训练模型的泛化能力,发现效果非常之好。
1、自然语言代码搜索
给定一段自然语言作为输入,代码搜索的目标是从一组代码中找到语义上最相关的代码。为了进行比较,作者选择了Husain 等人在2019年发布的 CodeSearchNet 语料库进行训练。这个语料库框架如下图所示,共包含6中常见的编程语言(Python、JavaScript、Java、Ruby、PHP、Go)。
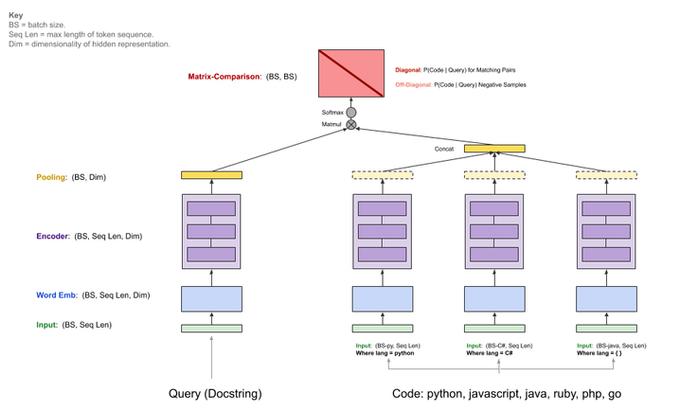
在预训练阶段,作者首先对每种语言的数据集进行了训练。数据集分割如下:
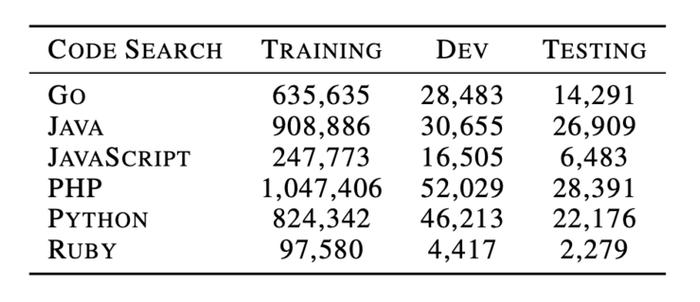
在微调阶段,设置学习率为1e-5,批量大小为64,最大序列长度为200,最大微调周期为8,并使用Adam来更新参数,并从开发集中选择出表现最好的模型,并用于测试集上进行评估。 结果如下表所示:
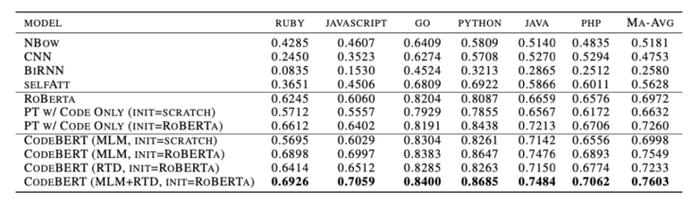
性能相比于之前的SOTA模型ROBERTa取得了显著的提高。
2、NL-PL Probing
这部分实验主要研究在不更改参数的的情况下,Code BERT能够学习哪些类型的知识。目前学界还没有针对NL-PLProbing的工作,所以在这部分实验中,作者自行创建了数据集。 给定NL-PL对,NL-PL Probing的目标是测试模型的正确预测能力。模型比较结果如下图所示:
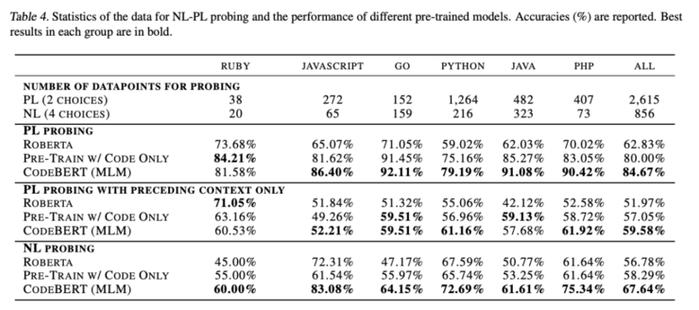
上表显示了正确预测实例的数量与全部实例数量的比例。可以看出,在各个变成语言的预测上,CodeBERT基本都取得了最高的分数。但由于不同编程语言的数据集非常不平衡,因此用累计的数据进行比较更为恰当,在PL和NL的probing中,CodeBERT的结果都要比RoBERTa高10~20个百分点。 也可以用一个具体的案例来对比下。下图案例中分别掩盖了NL和PL中的“min”:
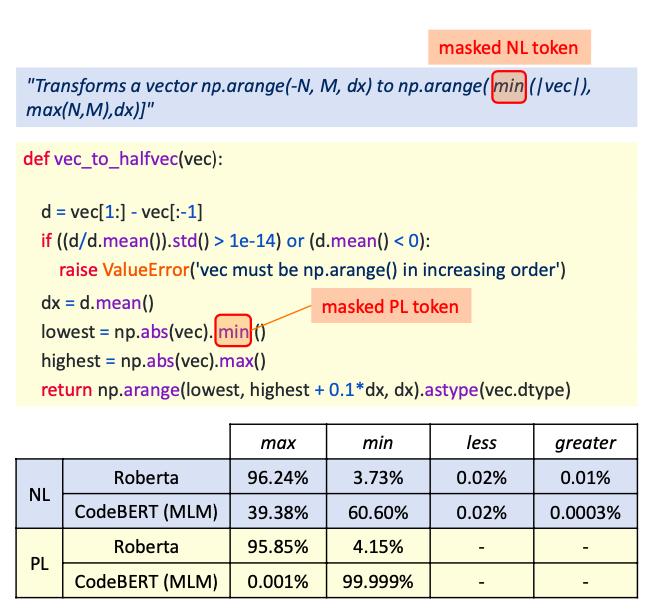
上图为RoBERTa和CodeBert的预测概率 从结果来看,CodeBERT在NL上的正确预测率为60.6%,而在PL上直接高达99.999%。
3、代码文档生成
这部分研究代码到文档的生成问题,并在六种编程语言中研究了生成任务在Code Search Net Corpus上的结果。 另外,为了证明CodeBERT在代码到NL生成任务中的有效性,作者采用了各种预训练的模型作为编码器,并保持了超参数的一致性。 实验结果如下:
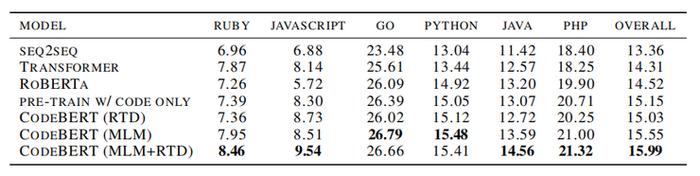
在编程语言上进行预训练的模型的性能优于ROBERTa
4、泛化能力
那么,在Python、JavaScript、Java、Ruby、PHP、Go这些语言上做的预训练模型能够应用到别的编程语言上吗? 作者拿着前面预训练出的CodeBERT模型在C#语言上做了测试。 作者选择了Codenn数据集,这是一个包含Stack Overflow自动收集的66015对问题和答案的数据集,其规模相比 CodeSearchNet语料库要小几个数量级。为了可靠地评估模型,作者通过人工方式,为测试集中的代码片段提供两个附加 titles 来扩展测试集。 模型评估标准采用平滑的BLEU-4分数,评估结果如下图:
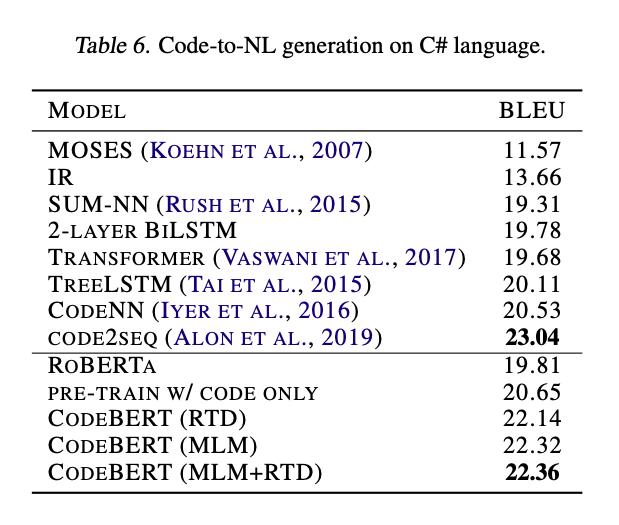
从这个结果可以看出,相较于RoBERTa,CodeBERT能够更好地推广到其他编程语言。不过值得注意的是,模型的效果略低于code2seq,作者认为原因可能是code2seq使用其抽象语法树AST中的组合路径,而CodeBERT仅将原始代码作为输入。
虽然作者也按照一定的顺序通过遍历AST的树结构来训练CodeBert,但并不会带来生成任务的改进。这种结果意味着结合AST来改进codebert是潜在方向。
四、总结
如前面提到,微软的 Bing 在2018年便已经上线了代码搜索功能,可以预期,基于预训练的代码功能也将很快落实到 Bing 的产品当中,从而提供能加优质的服务。同时我们也可以期待,该项工作能够在近期开源,以让更多研究人员快速跟进这一工作。
我们用几句话来总结这项工作的意义:
1、据作者表示,CodeBERT也是目前已知的首个大型的NL-PL(自然语言-编程语言)预训练模型;
2、本文提出了一个混合学习目标,能够支持使用双模数据NL-PL,且能够很容易地应用到单模数据中(例如没有自然语言文本的编程代码);
3、CodeBERT在自然语言代码搜索和代码文档生成两个任务中都达到了SOTA性能,此外作者在实验中还建立了一个数据集来研究NL-PL预训练模型的探测能力,方便了以后跟进的研究人员。
雷锋网原创文章,未经授权禁止转载。详情见转载须知。

