

如果将 Adam 优化出现以来产生的关于优化过程的有趣想法按时间顺序排列的话,结果如下:
LR Range test + Cyclical LR(《Cyclical Learning Rates for Training Neural Networks》)
SGDR(《SGDR: Stochastic Gradient Descent with Warm Restarts》)
SGDW(R) and AdamW(R)(《Fixing Weight Decay Regularization in Adam》)
1-cycle policy and super-convergence(《Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates》)
这个来自 Andrej Karpathy 的笑话或多或少是我深度学习项目的一套流程。除非把具有学习率硬编码的代码直接从 GitHub 里复制到所选优化器中,否则我可能只会把 3e-4 放到 Adam 优化器中,然后让模型训练。如果损失减少,今天就可以收工大吉。
但是,那些美好的日子已经一去不复返了。所以在这篇博客中,我将概述一些人们想出来推翻 Adam 的方法。
LR Range Test:不再盲目找最佳学习率
在这之前,如果 3e-4 在我的数据集上无法作用于模型,我会采取两个办法:
如果看不到损失值移动的明确方向,我会降低学习率。
如果在小数点后 5 或 6 位才能看到损失减少,我会提高学习率。
如有必要,我会再重复上面的过程。
2015 年,Leslie N. Smith 将上述的反复试验法形式化为一种名为 LR Range Test 的技术。这个方法很简单,你只需将模型和数据迭代几次,把学习率初始值设置得比较小,然后在每次迭代后增加。你需要记录学习率的每次损失并将它画出。
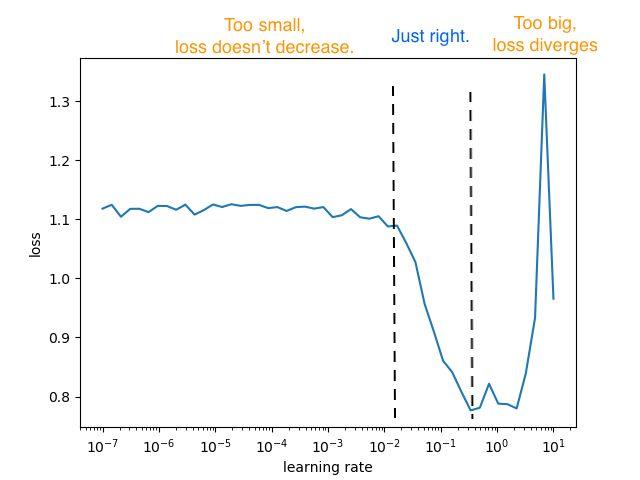
LR Range Test 图示。LR 的初始值仅为 1e-7,然后增加到 10。
LR Range Test 图应该包括三个区域,第一个区域中学习率太小以至于损失几乎没有减少,第二个区域里损失收敛很快,最后一个区域中学习率太大以至于损失开始发散。
除了确保你正在选择最佳学习率之外,该技术还可以作为一种「保险」检查。如果 LR Range Test 没有显示上述 3 个区域,或者图中有断层(损失中有 NaN 值),则表示模型中有缺陷或者数据中有错误。在运行模型之前,最好获取一个理想的 LR range 图。
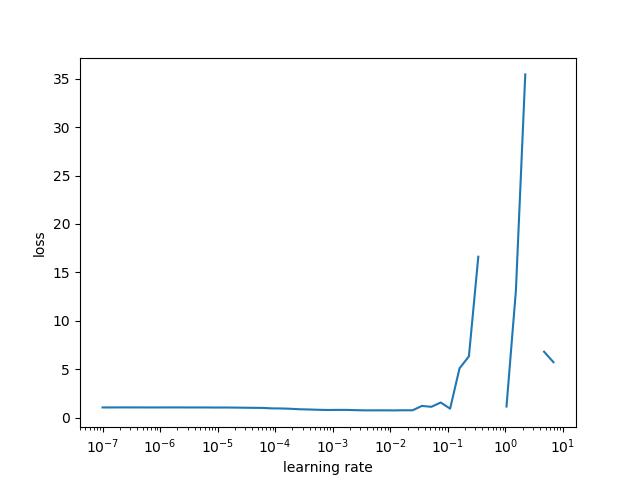
不好的 LR Range 测试结果。断层处也是损失具有 NaN 值的地方。
Cyclical LR :谁说 LR 需要下降
以往的常识是逐步降低学习率或使用指数函数,从而使模型收敛更稳定。
Leslie Smith 在同一篇论文中挑战了这一观点,他认为,与其单调地降低学习率,不如让学习率在合理范围内进行周期性变化,这样实际上能以更少的步骤提高模型的准确率。
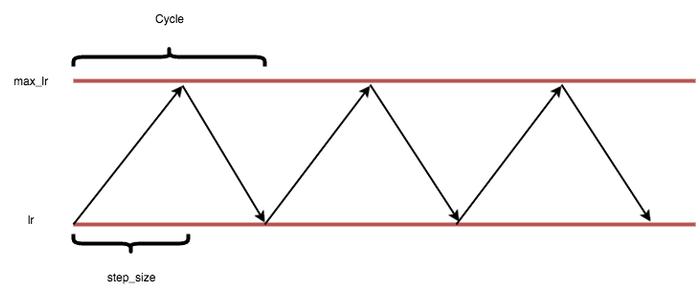
在 lr 和 max_lr 范围内循环学习率。
lr 和 max_lr 的范围可以通过上述的 LR Range test 技术来确定。这背后的原理是:最优学习率将在处于这个范围内,所以如果学习率在这歌区间变化,大多数情况下你将得到一个接近最优学习率的学习率。
作者讨论的另一个优点是能够在损失情况下避开鞍点。鞍点位置的梯度较小,因此小的学习率使模型在训练后期遍历这些鞍点时会很慢。通过在后期提高学习率,可以帮助模型更有效地摆脱鞍点。
Keras:https://github.com/bckenstler/CLR
Pytorch:https://github.com/anandsaha/pytorch.cyclic.learning.rate/blob/master/cls.py
SGDR:性能良好的旧版热重启 SGD
原则上,SGDR 与 CLR 本质是非常相似的,即在训练过程中学习率是不断变化的。
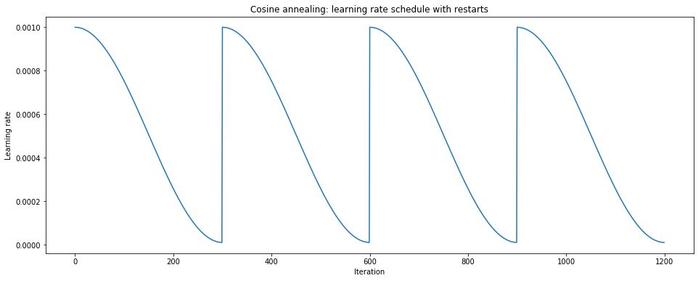
可重启和余弦退火的 SGD。图片来源:https://www.jeremyjordan.me/nn-learning-rate/
其中,主动退火策略(余弦退火)与重启计划相结合。重启是一个「热」重启,因为模型没有像全新模型那样重启,而是在重新启动学习率后,使用重启前的参数作为模型的初始解决方案。这在实现中非常简单,因为你不需要对模型执行任何操作,只需要即时更新学习率。
到目前为止,Adam 等自适应优化方法仍然是训练深度神经网络的最快方法。然而,各种基准测试的许多最优解决方案或在 Kaggle 中获胜的解决方案仍然选用 SGD,因为他们认为,Adam 获得的局部最小值会导致不良的泛化。
SGDR 将两者结合在一起,迅速「热」重启到较大的学习率,然后利用积极的退火策略帮助模型与 Adam 一样快速(甚至更快)学习,同时保留普通 SGD 的泛化能力。
Keras:https://gist.github.com/jeremyjordan/5a222e04bb78c242f5763ad40626c452
关于 Pytorch 的 PR: https://github.com/pytorch/pytorch/pull/7821/files
AdamW 和 SGDW:错误的权值衰减
「热」启动策略非常好,并且在训练期间改变学习率似乎是可行的。但为什么上一篇论文没有扩展到 AdamR 呢?
论文《Fixing Weight Decay Regularization in Adam》的作者曾说:
虽然我们初始版本的 Adam 在「热」启动时性能比 Adam 更好,但相比于热启动的 SGD 没有什么竞争力。
这篇论文指出,所有流行的深度学习框架(Tensorflow,Pytorch)都在错误的权值衰减中实现了 Adam。作者在论文中提出了以下意见:
L2 正则化和权值衰减不同。
L2 正则化在 Adam 中无效。
权值衰减在 Adam 和 SGD 中同样有效。
在 SGD 中,再参数化可以使 L2 正则化和权值衰减等效。
主流的库将权值衰减作为 SGD 和 Adam 的 L2 正则化。
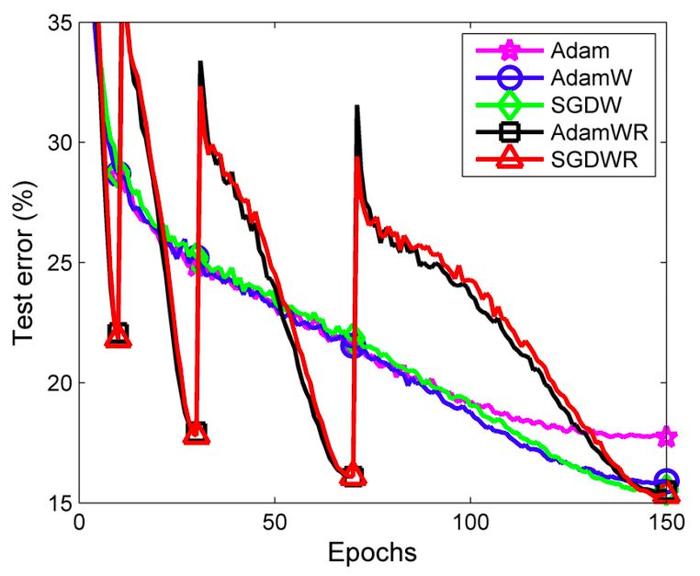
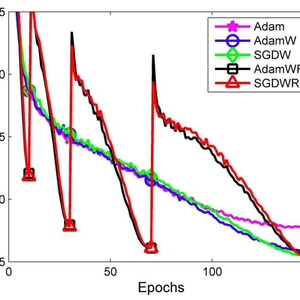
ImageNet 上的前 5 个测试错误,图片来自原论文。
→他们提出了 AdamW 和 SGDW,这两种方法可以将权值衰减和 L2 正则化的步骤分离开来。
通过新的 AdamW,作者证明了 AdamW(重启 AdamWR)在速度和性能方面都与 SGDWR 相当。
更多细节请参考: https://www.fast.ai/2018/07/02/adam-weight-decay/
在 Pytorch 和 Keras 中有一些针对此修复的请求,所以你应该很快就可以直接从库中使用这个。
一周期策略和超收敛
在 2018 年的近期工作中,LR Range test 和 CLR 的作者将自己的想法推向了极致,其中循环学习率策略仅包含 1 个周期,因此称作「一周期」策略。
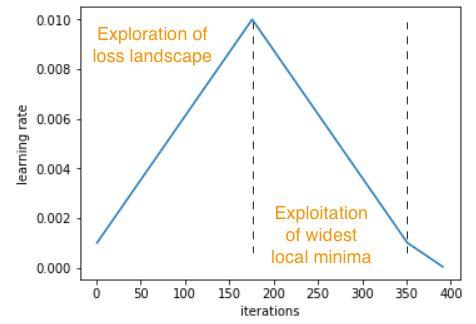
在一周期策略中,最大学习率被设置为 LR Range test 中可以找到的最高值,最小学习率比最大学习率小几个数量级。
整个周期(向上和向下)的长度被设置为略小于训练周期的总数,这样循环结束后有残余时间降低学习率,从而帮助模型稳定下来。
我们可以将这种策略看作是一种探索-开发的权衡,其中周期的前半部分更有可能从某一局部最优跳到另一局部最优,从而有望在最平坦、最广泛的局部最优区域达到稳定。以较大的学习率开始循环的后半部分有助于模型更快地收敛到最优。
一周期策略本身就是一种正则化技术,因此需要对其它正则化方法进行调优才能与此策略配合使用。
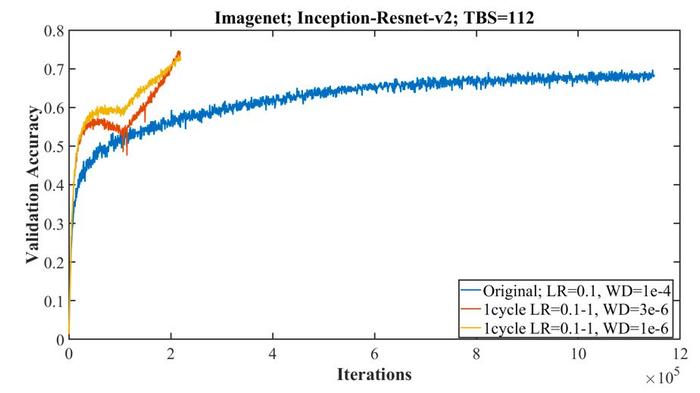
在 Imagenet 上训练 Inception-Resnet-v2 时的超收敛。
通过这一策略,作者演示了「超收敛」,它达到相同的验证准确率只需要 1/5 的迭代。
这种现象特别值得注意,因为随着可用的标记训练数据受限,收敛效果会增加。
更多细节请参考:https://sgugger.github.io/the-1cycle-policy.html
结论
所以在 2018 年,你应该做什么来代替 3e-4 Adam 工作流程呢?有很多东西需要考虑,如批量大小、动量等。但是,更好的工作流程将是:
使用 LR Range Test 找到最佳学习率,并完整地检查当前模型和数据。
始终使用学习率调度器,该调度器会改变上一步中找到的学习率,可以是 CLR 或 Restart。
如果需要 Adam,请使用具有适当权值衰减的 AdamW,而不是当前流行框架中使用的默认权值衰减。
如果想实现超收敛,可以进一步尝试一周期策略。
