



欢迎关注“创事记”的微信订阅号:sinachuangshiji
文/夏乙 栗子
来源:量子位(ID:QbitAI)
一段吐槽视频今天在美国火了。
也就半天的工夫,这段视频在Twitter上有200多万次播放,1300多条评论,被转发了2万6000多次,还收获了5万多个赞。
什么视频这么万人瞩目?主角,是前总统奥巴马;这么受关注,当然是因为——内容非常劲爆,特别是这一句:
President Trump is total and complete dipshit。
“川普总统完全就是个笨蛋。”
不过,这些劲爆的话都不是奥巴马自己说的,视频里的声音来自刚刚在今年的奥斯卡上以《Get Out》拿下最佳原创剧本奖的导演Jordan Peele。
他和BuzzFeed CEO Jonah Peretti一起,自导自演了这么一出大戏,戏里的奥巴马,对口型能力强大到让所有假唱精英败下阵来。

搬出奥巴马,就是为了向全美国(甚至全球)人民传达视频开头的那句话:
“我们已经进入了这样一个时代,我们的敌人可以做出看起来像任何人在任何时候说任何话的东西。”
未来的假新闻可能就是这个样。
这个视频……鹅厂不让上传,有兴趣的同学可以自行搭梯子去Twitter看:
视频中,Peele还放出了奥巴马和自己的对比环节。

右边就是Jordan Peele,这段视频的(部分)替身演员和声优。视频制作的主力工具则是Adobe AE和FakeApp。
此次的脸部搬家工作,具体是这样的。首先,找出一段奥巴马真正的演讲视频,将Peele的嘴粗暴地粘贴到奥巴马脸上。然后,再把奥巴马的下巴,换成一个可以随着演员嘴部动作一同运动的下巴。
下一步,FakeApp登场,负责把拼贴好的视频做一些平滑和细化处理。听起来像是收尾工作,但这一步任重道远。
据BuzzFeed透露,一开始搬家的效果蠢蠢的。可能用整容失败都不足以形容。但,训练时间长了之后,Peele的嘴部动作和奥巴马的脸融合得越来越自然。
最后发出来的视频,是56小时辛苦训练、以及特效专家现场指导的结晶。
又见FakeApp
是的,又见FakeApp。
去年底,一位不愿透露姓名的用户deepfakes,利用业余时间搞出了这个机器学习算法,主要的功效就是两个字:换脸。
只要给这个AI一些照片,就能出色的给视频中的主角换脸。
后来他的网名,就成了这个技术的代名词。作者本人透露,这个系统是基于像TensorFlow后端的Keras等多个开源库完成的。
这个开源系统发布之后,立刻引发了轰动。国外网友在reddit上创建了专门的讨论区,用来交流和发布研究成果。
简单实用效果好,deepfakes快速流行开来。很多人开始用这个技术,把色情片主角的脸换成自己喜欢的明星。
再后来,deepfakes进化成FaceApp。
从此换脸的流程进一步简化。FaceApp被定义为一个社区开发的桌面应用,可以运行deepfakes算法,无需安装Python、TensorFlow等,并且如果想要运行,仅需要“CUDA支持的高性能GPU”。
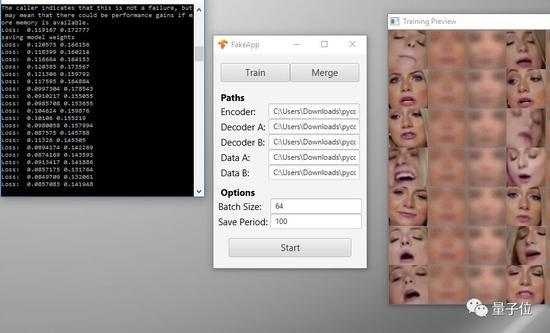
△ 换脸的训练过程
炸裂的效果引发了巨大的争议,后来reddit上这个版块也不得不关闭了事。
虽然互联网公司几乎集体封禁了deepfake相关社群,不想让网民们再到处传播换上赫敏脸的小片片。但是,这个技术的超低门槛软件FakeApp悄然迭代着,目前已经到了2.2版。
这里,我们放一段之前的演示:将希特勒的脸“嫁接”到阿根廷总统Mauricio Macri身上,体会一下效果。
关于deepfakes的应用,量子位还在另一篇报道里有过详细的描述,传送门在此:《不可描述,技术进步》。
无需配音
在FakeApp的帮助下,换脸这件事变得非常简单。
那声音怎么办?严丝合缝的声优在哪里?
还是让AI来吧。
上周,有Reddit小伙伴发布了,川普演讲的韩文版,是AI自动生成的。
楼下,就有韩国友人鉴定,嗯,流利得可以。
这还不算,会说韩文的群众纷纷表示,美国人说韩文,基本就是这个口音。
本周,还是那个小伙伴,又放出了带有you-know-who嗓音的韩式英文,AI调教成果上佳。
视频那一头的神秘团队Icepick,到底对他们的AI做了什么,目前并没有相关信息公开。

△ 耳朵会怀孕
不过,我们依然可以看看,AI获得语音生成技能之前,到底需要经受怎样的调教——
气质如何调教
不管是谷歌娘,Siri,或是Alexa,说的话听上去都不太像真人。这是因为,我们说话时有一些平常不容易察觉的细节,比如字与字之间的连接、呼吸声、气音、嘴唇碰撞时发出的声音等等。
所以,把多个语音片段直接拼接合成 (Concatenative Synthesis) 一段话 (即鬼畜本畜),或者用参数合成 (Statistical Parametric Synthesis) ,都很难产生非常接近人声的语音。
第一个用神经网络来生成人类自然语音的,就是DeepMind的WaveNet。

从前,人们很少为原始音频的声波直接建模,因为每秒有超过16,000个采样点,让模型过于复杂,难于训练。
但当PixelRNN和PixelCNN发布之后,DeepMind便有了“借助二维图像的处理方式,来处理一维声波”的想法。

WaveNet是全卷积神经网络,卷积层里的扩张因子 (dilation factors) ,能让感受野 (receptive field) 随深度变化呈指数增长,并且覆盖数千个时间步 (timestep)。
有了延时采样机制,只要增加一层,就可以多关联一倍的时间范围,训练效果更佳。

△ 你听得出,我不是人吗
通过层层卷积,WaveNet便可以把PS痕迹明显的机器语音,转换成更加流畅自然的语音,与人类声音之间的差异大幅降低。
嗓音如何调教
去年,Lyrebird也发布了语音合成技术,基于音色、音调、音节、停顿等多种特征,来定义某个人的声音,然后借用ta的声音来说话。
据公司官方表示,通过大量的样本学习,神经网络只需要听一分钟的音频,就可以模仿里面的陌生人说话了。Lyrebird系统生成一段语音,比同一时期的WaveNet要快得多。
口音如何调教
说一句话很容易,但语音就是一门复杂的学科了。同样一个“啊”字从不同的人嘴里发出来,也会因为口型大小、发音位置 (这并不是官方特征分类) 等习惯的不同,让身为听众的人类或计算机感受到差异。
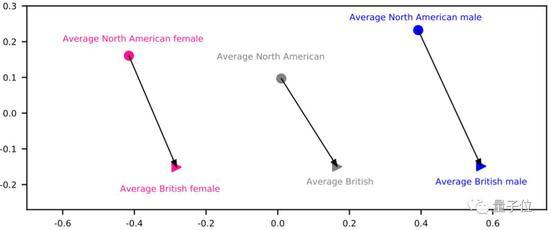
△ 给你,销魂的伦敦腔
百度的语音合成系统DeepVoice,可以轻松训练AI合成百种英文口音。研发团队发现,AI把不同口音的演讲者,对应到嵌入空间的不同区域里。比如来自大不列颠岛和北美大陆的人,在嵌入空间里占据的区域也有明显的不同。
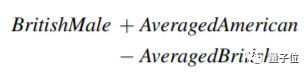
△ 简单的原理:英男 + 均美 +均英 = 美男
如果是处理中文,什么样的声线和口音,才比较适合骗大神带你吃鸡呢?
随口一说

△ 你个火·箭男
也有人不喜欢用政治噱头来包装科学研究的做法,并表达了强烈的反胃之情。
不过我倒觉得,如果有人发糖,还是要尽量分享给周围的人。下面是正确示范——川川当选之际,和希拉里的深you情du对唱 (误)。
以后,AI说不定能帮我们,把天衣无缝的南腔北调,P给鬼畜区的任何一位主角。
那么,我心心念念的雷布斯同款仙桃普通话,感觉指日可待啊。


