
发布日期:2010年03月16日 作者:蒋尚文 编辑:蒋尚文
第1页
泡泡网显卡频道3月16日 两军交战,阵前能斩落敌方武将于马下,则士气大振,已然胜了一半。而在PC领域,处理器和显卡等核心产品线的战场上也是同样的道理,旗舰级显卡作为各自最强3D图形性能得代表,肩负着展示技术、树立形象、打击竞争的特殊使命。
NVIDIA和AMD两大巨头之间每一次顶级产品的对决都可以用惊天地、涕鬼神来形容!对于消费者来说,新旗舰的性能总能给人惊喜,更让人激动的是那些首次应用的新技术和特效:革命性的架构往往就是从旗舰显卡开始!

两大图形巨头之间的竞争变得越发激烈,半年更新、一年换代早已成为显卡领域墨守成规的定律。而每当新王者推动改朝换代之时,我们也会于第一时间为大家献上详细的评测文章。岁月如斯,显卡已经伴我们走过十余载,每每想起TNT时代的时光,曾经的感动就涌上心头,今天我们就来缅怀一下昔日的王者,重新寻找落寞的皇族!
第2页
在Riva 128面世之前,NVIDIA还只是一家默默无闻的小公司,处女作NV1是款声卡显卡二合一的产品,未能得到众厂商认可;NV2胎死腹中;而NV3则依靠对微软Windows系统的完美支持以及Direct3D标准的壮大一举成名,称为当时图形霸主3DFX的强力竞争对手!
● Windows 95和Direct3D开辟电脑图形新战场

Windows 95的震撼力远大于如今的Windows 7
1995年8月,微软发布了Windows95操作系统,凭借崭新的图形交互式界面设计,很快席卷了全球个人电脑市场。在PC领域,微软的成功是空前的,几乎没有遇到任何可以匹敌的对手。微软的Windows95操作系统凭借接近90%(PC OS)的市场占有率,直接代动了相关硬件产品的需求,也使得全球的硬件软件厂商都不得不向其靠拢。由于微软的Windows95采用图形交互式界面(GDI),对于显示芯片有了更高的要求,这也正式揭开了电脑图形市场的龙争虎斗!
在之前的1995年2月,微软收购英国Rendermorphics公司,利用其所有的RealityLab 2.0技术制定了Direct3D标准,整合在其WINDOWS操作系统中,对PC图形芯片市场产生了巨大影响。
● NV3=Riva 128,首次大获成功:
此时的NVIDIA总结了前2款芯片的经验教训,在经过细致的市场分析之后,将研发的方向定位于市场前景广阔的PC图形芯片市场,并且决定加入对DirectX的支持。这无疑是个非常明智的选择,在当时由于3DFX的GLIDE的成功,各家显示芯片公司纷纷效仿,也想推出自己的3D API,例如,3dfx有GLIDE、PowerVR的PowerSGL、ATI的3DCIF,无疑使得微软Direct 3D的推广十分缓慢,NVIDIA此时选择旗帜鲜明的站到了Direct 3D的一边,这种做法也受到了微软的赏识,从而有了一个坚强的后盾。
另外,当时在3D FPS游戏市场,独领风骚的是ID SOFRWARE的QUAKE系列,而其程序设计师JOHN CARMARK明确的拒绝了3DFX采用GLIDE的建议,而是基于公开的OPENGL API开发,这无疑也是NVIDIA得以崛起的另一个因素。而且,经过时间的考验,至今这两家公司仍然保持了非常好的关系。后来在Quake3的硬件加速问题上,John Carmack甚至拒绝提供任何形式的MiniGL加速,而要求所有图形卡运行在OpenGL ICD环境下,使得3DFX相当难堪。

RIVA 128(NV3)
接着,为配合研发方向的转变,NVIDIA聘请了David Kirk(NVIDIA首席科学家,现已当选美国国家工程院院士),并将其任命为技术总监。1997年,NV3终于面世,被命名为RIVA 128。它也是第一个提供硬件三角形引擎的128 bit图形芯片,虽然RIVA 128的图像质量比不上3dfx Voodoo,但是凭借100M/秒的像素填充率和对OPENGL的良好支持,RIVA 128在非GLIDE API的游戏中完全超过了Voodoo,迅速赢得了消费者和一些OEM厂商的青睐。

RIVA 128显卡
Riva128支持AGP 1x规范,可以配合Intel的LX芯片组主板使用。1997年底,Dell、Gateway等厂商相继使用了RIVA 128显卡。零售市场上,Diamond、STB、ASUS、ELSA和Canopus等也都相继推出了基于此芯片的产品。不到一年,Riva 128的出货量就突破100万颗,NVIDIA终于凭借NV3打了个翻身仗。
总的来看,Riva 128取得成功的因素是多方面的,本身的处理性能固然很重要,但是1998年游戏软件方面的发展变化也很关键:
首先,年初ID开放了QUAKE2引擎的授权,包括VALVE在内的游戏软件开发商在3月份就获得了QUAKE2引擎的源代码,并用于游戏的开发,使得QUAKE2引擎的3D游戏名作诸如《异教徒》、《半条命》等大量上市,Riva 128良好的OpenGL性能得到了充分的发挥。
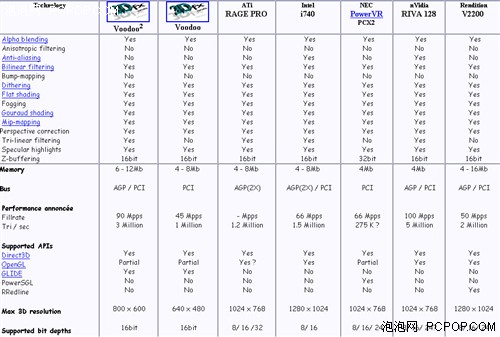
第3页





名称 | RIVA TNT | RIVA TNT2 |
架构 | NV4 | NV5 |
制造工艺 | 0.35 Micron | 0.25 Micron |
晶体管数目 | 7 Million | 15 Million |
DirectX支持 | 6 | 6 |
顶点管线 | 1 | 1 |
VS版本 | - | - |
像素管线 | 2 x 1 | 2 x 1 |
PS版本 | - | - |
核心频率 | 90 MHz | 125 MHz |
填充率 | 180 MTexels/s | 250 MTexels/s |
显存位宽 | 128-bits | 128/64-bits |
显存类型 | SDR | SDR |
显存速度 | 110 MHz | 150 MHz |
显存带宽 | 1.76 GB/s | 2.40/1.00 GB/s |
从TNT2开始NVIDIA对产品进行了市场化细分,在高中低端,面向多种不同的用户,TNT2芯片衍生出TNT2 Vanta、TNT2 M64、TNT2、TNT2 Pro、TNT2 Ultra等不同的型号产品,搭配不同显存的容量,产品线覆盖了大部分的市场。

TNT2 Ultra
TNT2 Ultra是系列最高端产品,也是NVIDIA第一次使用Ultra后缀命名高端产品,TNT2 Ultra只是从NV6核心中挑选出的品质优秀的芯片,并搭配了速度最快的显存,其核心/显存频率高达150/183MHz,后期更是提高到175/200MHz,性能上超过了3DFX的VOODOO3 3500以及MATROX的G400 Max,而且支持的特效也很全面(比G400少一个EBM环境凹凸贴图),成为当时性能之王。当然TNT2 Ultra的售价也很高,当时丽台、华硕、创新等一线品牌TNT2 Ultra的国内上市售价高达2300元(1999年5月)。
TNT2标准版是高端系列的普及型产品,也是TNT2 Ultra的降频版,核心/显存频率为125/150MHz,但是由于TNT2采用0.25微米工艺,核心普遍可以工作在150MHz左右,所以也造就了良好的超频能力,于是众多游戏发烧友更倾向于购买TNT2标准版版超频至TNT2 Ultra来使用,记得当时甚至还有不少玩家超到了165/200MHz的水平,性能也是也达到了一个新的高度。价格上TNT2标准版也更有优势,32MB显存的TNT2国内上市售价为1500-1750元左右,16MB的TNT2 Pro则在1350-1500左右。
● NV6=NV5工艺改进版,TNT2 Pro/M64/Vanta诞生

后期随着制程的进步,NV6也使用了0.22微米工艺,并被命名为TNT2 PRO,也被用于部分TNT2 Ultra。由于使用0.22微米制程后,TNT2 PRO的成本、功耗有、发热有明显下降,超频能力更强,性价比进一步提高。除了高中端的TNT2标准版外,NVIDIA同时也利用0.22微米工艺的NV6芯片,推出了针对中低端用户的TNT2 Vanta和TNT2 M64。
第4页

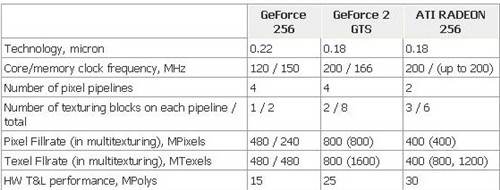
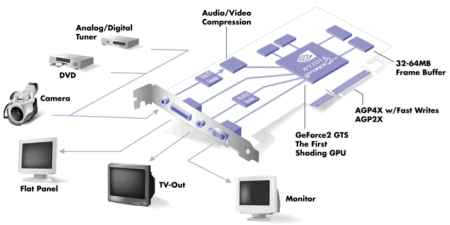
Geforce 256具有了现代GPU的大部分的初步特征,核心采用了256位渲染引擎,具有4条象素管线,每管线一个纹理映射单元,它也是第一个使用DDR显存的PC显卡。Geforce 256核心频率为120MHz,三角形生成率为1500万个/秒,峰值像素填充率达到480 M/s,并使用了四纹理(Quad Texel)引擎,相同频率下,Geforce 256的纹理处理性能是TNT2的两倍。特效方面,支持立方体环境映(Cube environment mapping)以及顶点混合、纹理压缩和凹凸映射贴图等。视频方面,为了加强为MPEG-2视频回放性能,NV10中加入了硬件动态补偿功能。


GeForce 256 SDR
GeForce 256 SDR版的售价上有不小的优势,在国内的售价至少比GeForce 256 DDR要便宜500元。其显存频率为200MHz,带宽2.4GB/S,这样对NV10核心的性能有了不小的限制,高分辨率、32为色深下的性能下降很大,几乎和TNT2 Ultra相近,但由于成本下降不少因此销量也不错。
第5页



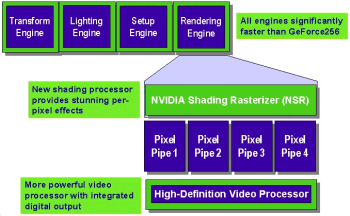
GeForce2上也首开了PC图形核心通用计算的先河,凭借其强大的多纹理处理性能,结合纹理环境参数和纹理函数可以实现一些很灵活的应用。它具有Texture Shader以及Register Combiner单元,有一定的数值计算能力。开发人员可以利用Texture Shader的依赖纹理进行数据访问,用Register Combiner进行计算。GeForce2被用于求解数学上的扩散方程,成为GPU通用计算的最早应用。





GeForce 3 Ti


第7页


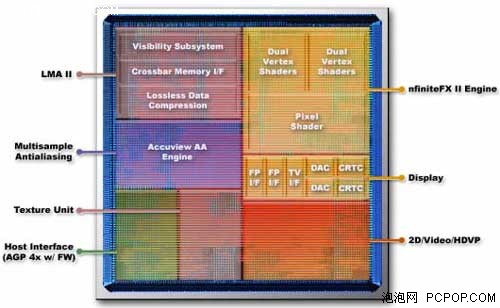
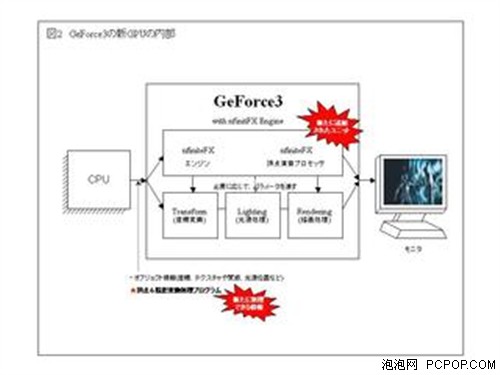
GeForce4 Ti采用了第二代nfiniteFX 引擎,它是从GeForce3时代开创的nFiniteFX引擎改进而来的,顶点SHADER单元增加到2个,像素着色单元的效率显著的提升。GeForce4 Ti也同时引入了第二代LightSpeed Memory Architecture II(LMA II)光速显存构架技术,在全屏反锯齿方面,GeForce4 Ti采用了新的Accuview AA技术。从总体上看,GeForce4 Ti也是从GeForce3的加强优化版本,核心增加了一个顶点单元,同时频率也比GeForce3有了很大的提升。
● 生不逢时的钛极4800:
2002年底,市场正式开始从AGP4X向AGP8X过渡,NV也顺应时势的推出了GF4 TI4200/4800-8X,除了接口带宽升级之外,频率也略有提升,性能更上一层楼。

但在此时,微软的DirectX 9 API标准已经成型,ATI率先发布首款DX9显卡Radeon 9700/9500,不但性能上完全超越了GeForce Ti 4000系列,而且支持新的图形标准,这对NVIDIA造成了不小的压力。而此时NVIDIA全新架构的GeForce FX系列正面临制造工艺和技术方面的难题,屡次延期导致产品线青黄不接。
第8页
2002年11月18日,Comdex 2002上,NVIDIA发布了研发代号NV30的GeForce FX,这也成了历史上NVIDIA最具争议的一款产品。在回顾GeForce FX系列产品前,我们不妨先对NV30的问世背景做个简单介绍。

不过NVIDIA的一家独大也引起了一些业内人士的不满,他们指责NVIDIA是图形业内的Intel。当然这也使与NVIDIA一贯合作良好的微软有所注意,尤其是NVIDIA在DirectX 8标准制定过程中的某些做法以及开发自主的CG语言等,使得微软不等不重新审视这个昔日的合作伙伴,两家公司的开始逐渐变得貌合神离。




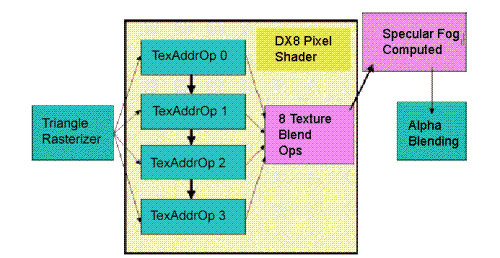
在CineFX着色引擎中,具有32个128位浮点处理器。并在PC图形核心历史上首次提供了128bit色彩精度的支持,并且可以在同一个着色程序中的不同色彩精度中切换。
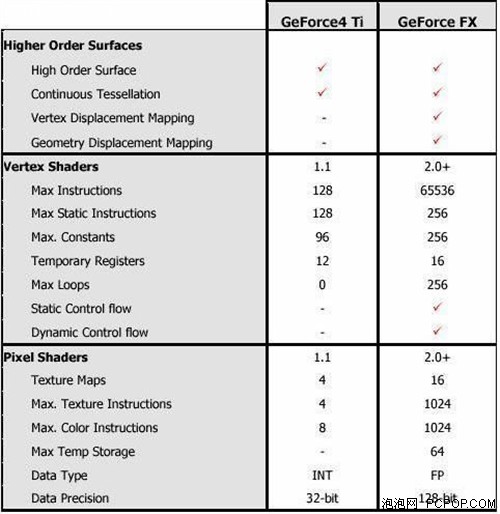
NV30的顶点着色单元较前代也有了质的飞跃,可以支持到Vertex Shader 2.0+,所能处理的最大指令数为65536,这一点远远高于DX9.0的规范。而且,初级的动态循环和分支指令的引入提高了着色单元的可编程性。像素着色单元支持Pixel Shader 2.0+,同样也超出了DX9.0规范,最大指令数提高到1024,对于每一个像素最大可进行16个纹理贴图操作,而且像素单元可以支持更多的高级指令,并且可以进行指令预判。总的来说,CineFX引擎支持更多的指令,因此可以带给开发者更大的发挥空间。
同时CineFX引擎也可以很好的支持NVIDIA的Cg(C for Graphics)编程语言,使得开发人员可以利用Cg语言而无需针对底层硬件进行编程,从而降低了图形编程的难度,可以更方便、快捷的开发出游戏所需要的渲染效果
在反锯齿方面,4X FSAA是NV30设计的中心,也是NV30硬件效率最高的操作。为了使4X FSAA运行更快,NV30在反锯齿设计上进行了重新制定,每个数据通道的宽度都为4X FSAA做了优化。同时,NV30还首次采用了Intellisample(智能采样)、(Adaptive Texture Filtering)自适应纹理过滤等技术一提供更好画面质量。

在内存控制方面,NV30采用了4X32bit共128bit的位宽。由于采用了全新的DDR-II显存,所以NV30在GeForce 4的LMA II的基础上(Lightspeed Memory Architecture,光速内存结构)针对DDR-II做了相应的优化设计。这款内存控制器实际上是全新设计,对4X FASS进行了全速优化。ROP(光栅化处理器)、帧缓存等都是根据它来设计的。而且它运行在2X的核心频率上,可以充分利用DDR-II的特性。
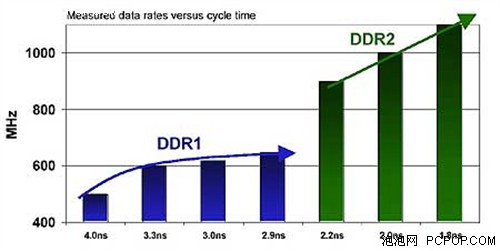
GeForce FX 5800 Ultra的DDR-II SDRAM显存运行频率为1GHz,不过由于是128BIT位宽,和对手的Radeon 9700相比,其峰值带宽落后25%。但由于新型LMA内存控制器提高了Z-culling和压缩方面的性能,顶点、纹理和Z轴数据都进行了压缩以节省带宽,在程序配合较好的情况下,NV30可以更有效的使用带宽。再加上Z-occlusion和纹理压缩等技术,GeForce FX 5800 Ultra的实际最大带宽可以达到20GB/s。
第9页
现在回过头来看,NV30在架构的设计上还是存在着不少问题,其中最主要的就是Piexl Shader的处理能力低下。由于NV30的Piexl Shader单元没有co-issue(标量指令+矢量指令并行处理)能力,而在DirectX9.0中,单周期3D+1D是最常见指令处理方式,即在很多情况下RGB+A是需要非绑定执行的,这时候NV30就无法并行执行,指令吞吐量大大降低。其次,NV30没有miniALU单元,也限制了NV30的浮点运算能力。
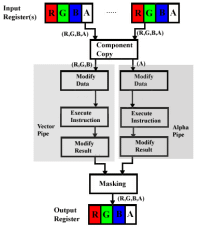
另外,NV30在寄存器设计(数量及调用方式)、指令存储方式(读写至显存)等方面也有缺陷。NV30的寄存器数量较少,不能满足实际程序的需要。而且,用微软的HLSL语言所编写的pixel shader2.0代码可以说NV30的“天敌”,这些shader代码会使用大量的临时寄存器,并且将材质指令打包成块,但是NV30所采用的显存是DDR-SDRAM,不具备块操作能力。同时,NV30材质数据的读取效率低下,导致核心的cache命中率有所下降,对显存带宽的消耗进一步加大。
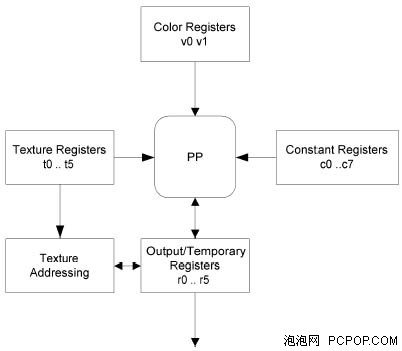
寄存器调用
同时,由于NV30是VILW(超长指令,可同时包含标量和SIMD指令)设计类型的处理器,对显卡驱动的shader编译器效率有较高的要求。排列顺序恰当的shader代码可以大幅度提升核心的处理能力。NVIDIA也和微软合作开发了"Shader Model 2.0A",可以为NV30产生更优化的代码。在早期的一些游戏中,这种优化还是起到了一定的作用。但对于后期Shader运算任务更为繁重的游戏则效果不大。
从宏观上说,NV30的整体架构更像是一个DirectX7(固定功能TRUE T&L单元)、DirectX 8(FX12combiner DX8整数处理单元)、DirectX 9(浮点像素单元)的混合体。而在DirectX 9的应用中,不能出现非浮点精度的运算,所以前两者是不起作用的,造成了NV30晶体管资源的浪费,同时也影响了性能。而NV30这种DirectX 7、8、9三带同堂的架构也让我们想起了一个至今仍在广泛使用的3D测试软件: 3DMark03——这会是一种巧合吗?
虽然NV30的架构决定了它在DirectX 9游戏中的表现不会很好,但是由于在整个2003年,DirectX 9并未成为游戏开发的主流,所以NV30的架构缺陷并未暴露出来。即便如此,NVIDIA还是意识到了NV30的一些不足,并迅速对NV30的像素着色单元做出了改进,并于2003年5月的GDC上,发布了新一代研发代号为NV35的5900系列。

● 亡羊补牢之作——NV35,FX5900
NV35芯片采用更加成熟了的0.13微米铜互联工艺,芯片的良率比NV30大幅度提升。核心面积为40mm×40mm,采用1309针FCPGA封装,内部晶体管数量达到了1.3亿。虽然比NV30又增加了500万个晶体管,不过通过改进的工艺,NV35的发热量略有降低,因此没有搭配Flow FX散热系统。
新的NV35采用了CineFX2.0引擎,和第1代CineFX相比,NVIDIA对Piexl Shader做出了一定的改进,在保留FX12 combiner的同时增加了两个可进行浮点运算的miniALU,虽然miniALU的功能有限,但是还是使得NV35的浮点运算能力提高了一倍。
NV30中的CineFX2.0还改进了Intellisample(智能采样)技术,增加了更多的高级纹理、色彩以及Z轴压缩算法以提升图象质量,并重新命名为“Intellisample HTC(高分辨率压缩技术)”技术。
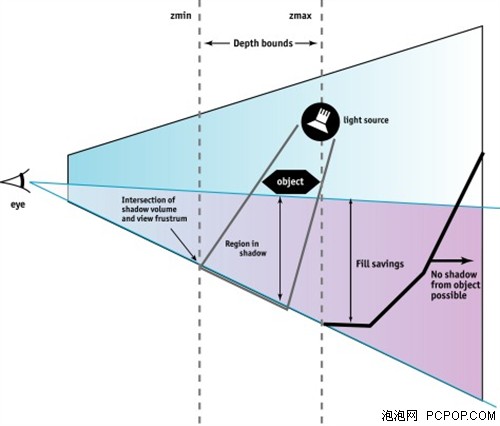
CineFX 2.0引擎引的另一个改进是引入了UltraShadow的技术。UltraShadow也可以说是为IDSoftware的新一代DOOM3引擎量身打造的,因为DOOM3引擎大量采用了体积阴影技术(Volumetric Shadow),Shadow Volume可以更加精确的表现动态光影效果的场景,但由于阴影体积引入了额外的顶点和面,也加大了光影计算的强度。而Ultra Shadow可以简化光影计算的过程,它允许程序员定义场景中一个区域,将物体的阴影计算限定在一个特定范围内,从而加速阴影的计算速度。此外,UltraShadow技术还允许程序员在一些关键的区域对阴影进行调整,从而创造出可与真实情况媲美的优秀视觉效果。Ultra Shadow还能利用Intellisample HTC技术以确保阴影边缘的

NV35刚发布时有两个版本——GeForceFX 5900和5900 Ultra,核心频率分别为400MHz和450MHz,而显存频率都是850MHz。因此显存带宽达到27.2GB/s,不仅远远超过GeForceFX 5800 Ultra的16GB/s,也比Radeon 9800Pro的21.8GB/s高出不少。
虽然在5月发布的5900系列为NVIDIA在高端产品线挽回了不少损失,但是在市场规模、利润最大的中端方面,却面临更严峻的形势,由于ATI在3月发布了RV350,也就是Radeon 9600 系列,再加上因为具有修改潜力而已经颇具人气的Radeon 9500,使其竞争力大幅度提高,而NVIDIA则只能由经典但已显老迈的TI 4200、新一代的5600 Ultra来抵挡ATI的攻势,但是早期的5600 Ultra(350/700)因为自身架构和频率的原因,难以独当一面,在一些应用中性能甚至不敌Ti4200。后期的高频版5600 Ultra(400/800)则迟到了近2个月而且产量有限,业界还传出了NVIDIA在GeForce FX 5600 Ultra的生产上遇到了困难的消息。总之,NVIDIA的一系列变故使得ATI在中端主流市场轻松的获得了领先。

显然由于市场竞争的激烈态势,GeForce FX 5700 Ultra才是这次发布的重头戏。GeForce FX 5700芯片的开发代号为NV36,目的是替代GeForce FX 5600和GeForce FX 5600 Ultra。NV36内部集成了8200万个晶体管,虽然同样为4X1架构,具有4条像素管线及每管线一个TMU单元,由于继承了NV35的Cine FX2.0体系架构和Ultra Shadow阴影加速技术,顶点处理能力、特别是浮点性能比NV31提高了200%--300%。显存方面和NV31相同,使用了两个64-BIT显存控制器支持128-BIT的显存位宽。
有鉴于在NV31核心的生产遇到的种种意外,这次NVIDIA 将NV36交由IBM 生产,GeForce FX 5700也是IBM与NVIDIA合作的第一款产品。不过GeForce FX 5900/5950仍由TSMC负责生产。和GeForce FX 5600一样,GeForce FX 5700也基于0.13微米工艺制造,但是IBM采用了低介电系数材料工艺(low-k dielectric),用来绝缘核心中的导体环路,在不增加功耗的情况进一步提升核心频率。
所以GeForce FX 5700 Ultra核心频率提高到475MHz,比FX 5600 Ultra高出75MHz。显存方面则搭配了日趋成熟DDR2的显存,工作频率900MHz,提高了性能的同时,也减少了功耗。后来,GDDR3显存的FX5700Ultra,GDDR2跟GDDR3的针脚是兼容的,所以不用重新设计PCB。由于GDDR-3的Latency比GDDR-2要高,所以将其显存工作频率升至950MHz 。
第10页
在经历了GeForce FX系列惨痛的失败后,NVIDIA痛定思痛、吸取教训,要挽回在高端产品上的失利局面,仅靠架构已完全定型的NV3x系列作一定程度的增补显然是很难实现的。实际上早在NV3x系列的时代,NV40的研发就一直在进行,并且进展很好。NVIDIA将更大的希望押宝在了这款具有划时代意义的新产品上。
● GeForce 6800 Ultra

奇特的NV45核心其实就是NV40搭配BR02桥接芯片
采用NV40核心的GeForce 6800系列显卡创造了很多项第一:
1.性能之王,NV40核心拥有16条像素渲染管线和6条顶点着色单元,虽然对手的X800也是同样的配置,但管线效率的不同导致ATI必须使用更新的工艺和更高的频率才能勉强战平6800Ultra。因此NVIDIA GeForce 6系列的旗舰产品只有6800Ultra这一款(只有NV40这一颗核心,分为AGP和桥接PCIE的两个版本),而对手则有X800XT、X800 XT PE、X850XT等很多工艺的核心及很多版本,而且都未能完全击败6800Ultra。
2.首款支持DX9C标准的显卡,而对手的Radeon X800系列仅支持DX9b,正所谓风水轮流转,ATI经历了DX9初代辉煌之后,也尝到了落后就要挨打的滋味;
3.率先推出支持PCI-E的显卡,NVIDIA采用的是桥接技术,而ATI采用原生方案导致产品推出较晚,NVIDIA在PCI-E时代来临之际抢得先机;
4.“失传”多年的SLI双卡互联技术重出江湖,NVIDIA依靠SLI技术轻松将图形性能翻倍,性能大幅领先与对竞争手,这也迫使ATI依靠第三方解决方案开发并不成熟的CrossFire技术。

SLI技术大显神威,迫使ATI“连夜赶制”CrossFire技术
GeForce 6的成功彻底打乱了ATI的阵脚,以致于频出昏招,产品线极为混乱,当初奚落NVIDIA的“有路不走何必搭桥”豪言壮语也食言了,正所谓三十年河东三十年河西。
第11页
● GeForce 7800GTX——半年内无竞争对手
在GeForce 6800Ultra大获成功的基础上,NVIDIA并没有在NV40核心的基础上改进高端产品,而是选择了进一步提升核心规模,由此诞生了拥有24条像素渲染管线的G70核心,性能遥遥领先于竞争对手。

7800GTX(256MB)
既不支持DX9C、交火技术也不成熟、性能方面更无法相提并论,此时的ATI面对GeForce 7800GTX是毫无还手之力,在此后半年多的时间内,7800GTX稳坐性能之王的宝座。而中低端产品6600系列也大获成功,因此NVIDIA并不急于推出基于GeForce 7架构的主流产品。

7800GTX 512MB由于频率大增发热不小,因此散热器改用双槽热管版本
终于在2005年底,ATI推出了首款DX9C产品X1800系列,但遗憾的是其R520核心依然只有16条像素渲染管线,即便依靠90nm工艺获得了超高的频率,但性能上还是无法完全击败7800GTX。不过未雨绸缪的NVIDIA也预留了一手,在X1800发布之后NVIDIA迅速推出了512MB显存版本的7800GTX,在显存容量翻倍的同时频率也大幅提升,此时的X1800XT根本没有任何取胜的机会。
● GeForce 7900GTX——避其锋芒,乘虚而入:
在2005年GeForce 7800GTX称霸图形市场半年之后,来自48个像素单元R580核心X1900XTX的挑战终于让NVIDIA下决心推出酝酿已久的7900GTX。G71核心架构与G70没有本质区别,可以把它看作是90nm工艺版的G70。但从G71核心上我们可以看到NVIDIA的另一种设计理念——与ATI R580完全相反的成本控制和功耗控制……




第12页
● GeForce 7950GX2——双拳出击,誓夺王位:
48个像素单元的X1900XTX核心实力可不一般,24管线的7900GTX明显不是对手,虽然它拥有功耗和成本上的优势,但旗舰产品代表的是性能与实力,NVIDIA不甘心就这么败给X1900XTX。
于是经过多方面的尝试之后,在6月份NVIDIA终于亮出了杀手锏——双核心、1GB显存的7950GX2显卡!得益于良好的兼容性和成熟的SLI技术,7950GX2在任何主板上都能发挥出真正实力,两颗G71联手就可以轻易的击败X1900XTX。



在7950GX2显卡身上,G71低成本、低发热、低功耗的优势再次得到体现:两颗G71加起来的核心面积同R580相当,双PCB设计使用了两块8层PCB,其成本要低于一块12层PCB,分离式供电模块也不复杂。最终7950GX2的售价依然维持在5000多元的价格,在这类“超级显卡”的阵营里 ,这样的价格是极具竞争力的!
X1900XTX性能再强,也不可能是两片7900的对手,在众多测试中7950GX2毫无悬念的击败了X1900XTX,终于夺回了性能之王宝座!

7950GX2虽然实力强悍,但它也有很多无法回避的缺点,由于7950GX2拥有两颗G71核心以及1GB显存,以往N卡在功耗、发热和噪音方面的优势不复存在,实际上7950GX2在这方面比起X1900XTX有过之而无不及!另一方面7950GX2是基于SLI技术的产物,一些新游戏、新特效无法有效的利用双核心,7950GX2的性能自然比较差,所以7950GX2严重依赖于驱动的优化!
虽然7950GX2夺回了单卡性能之王的称号,而且两片7950GX2能够组建四核心Quad SLI,但NVIDIA的Quad SLI驱动一直都不够成熟,直到被8800GTX所取代都没能发布一款令人满意的驱动,所以7950GX2双卡还是不敌ATI CrossFire,ATI之后发布的X1950XTX就是针对7950GX2而来的!
第13页
NVIDIA虽然依靠7950GX2重夺单卡性能之王的宝座,但在双卡方面Quad SLI很难取得突破,而且陈旧的GF7架构无法支持HDR+AA,事实上7950GX2只是权宜之计。而全新架构的G80才是NVIDIA更新产品线,从根本上击溃对手的重型武器,毫不夸张得说:GeForce 8800GTX的发布带领NV进入了一个黄金时代!
● 2006年11月8日 GeForce 8800GTX(G80)——DX10 统一渲染架构
G80核心的横空出世宣告了DX10时代的来临,8800GTX先于微软的Vista和DirectX 10发布,虽然当时没有任何一款DX10游戏(半年后才陆续面市),但8800GTX强大的DX9C性能已经给大家留下了深刻印象,双核心的7950GX2在8800GTX面前无地自容。




8800GTX强大的实力源自于多方面:从规格不难看出,G80是相当恐怖的一款GPU,核心拥有6.81亿个晶体管,是G71的2.5倍之多!这就奠定了G80庞大的渲染能力;其次颠覆传统Shader架构的标量流处理器,最大限度的提升了核心的执行效能;当然384Bit显存位宽也充分保证了数据吞吐能力;革命意义的架构以及强大的性能足以人为之疯狂!最后,由于发布时间很早,游戏开发商为NVIDIA新一代架构的鼎力优化与支持,也成就了其强大的DX10游戏性能。

当然G80也并非完美:它依然使用台积电90nm工艺制造,因此核心面积非常大,功耗以及发热也是再创新高,

G80的庐山真面目

顶级显卡自然是不惜成本、最高频率的配置,8800GTX超长的体形表明了自己的与众不同。8800GTX之所以这么长久是因为功耗太大使得供电模块变得非常复杂。8800GTX使用了12颗16M×32Bit规格的显存,组成了768MB 384Bit的配置,虽然没有使用GDDR4显存,但带宽已是再创新高。
由于之前我们对G80的架构以及核心引擎都进行了非常详细的分析与介绍,所以此处不再赘叙,感兴趣的朋友请看“为王位而生 GeForce8800全面解析测试”一文。
● 2007年5月8日,GeForce 8800Ultra(G80)
在得知竞争对手将会与5月份发布R600核心的HD2900XT之后,NVIDIA适时地放出了基于G80核心的高频版8800Ultra,当然这也是为了实现自家产品线半年更新的承诺。




严格来说8800Ultra并非全新产品,它只不过是将G80的制程从A2升级到A3,这样良品率和冲击高频的能力会好些;显存由1.0ns升级到0.8ns,另外散热器风扇作了些改进,虽然PCB没有任何变化,但是由于核心/流处理器/显存频率都提升不小,8800Ultra性能和GTX8800拉开了不小差距,顺理成章的成为新一代旗舰显卡。
第14页
● 2008年3月18日,GeForce 9800GX2(G92×2)
G80强大的性能让GTX8800和8800Ultra难逢敌手,但是功耗也成倍增加,这一软肋从根本上阻止了它的平民化,于是G92核心应用而生。作为G80的改良版,G92工艺从90nm进化到65nm使得它功耗、发热、成本大幅下降。但是NVIDIA对于G92的定位并非旗舰,因此使用了256Bit显存来进一步控制成本。虽然G92核心的纹理单元和高清单元比G80强很多,而且核心频率大幅提高,但显存位宽限制了它的性能表现,基于G92单核的9800GTX未能超越一年前的8800GTX。难道NV在高端不思进取么?当然不是,原来NVIDIA另有打算,当年双G71核心的7950GX2灵魂附体,双G92核心9800GX2震撼登场!




拥有7.54亿晶体管的G92核心本身功耗发热就不低(相对G80是好些),做成双核心显卡自然对供电和散热提出了很高要求,所以9800GX2显卡的结构和散热系统都是史无前例的复杂,全密封式设计完全就像是一块板砖。
性能方面单颗G92可以达到接近于8800GTX的水平,双核心性能提高80%,9800GX2自然完全超越8800Ultra成为毫无争议新王者。双核心本身的效率不容置疑,但其弊端就在于组建Quad SLI之后四核心效率不高,当年的7950GX2完胜X1950XTX,7950GX2 Quad SLI却不敌X1950XTX CrossFire。好在DX10时代NVIDIA重新设定了渲染模式,在驱动优化方面下了大功夫,随着更多新游戏对多GPU系统提供优化支持,9800GX2 Quad SLI系统的性能还是令人相当满意的,四颗G92核心将3D图形性能提升到了新的境界!
第15页
虽然NVIDIA和AMD的旗舰显卡性能差距较大,但双方的产品策略居然惊人的相似:G80和R600核心都是采用较老的成熟工艺,将晶体管堆到极限的产物,也就是通过暴力手段、不惜成本(512/384Bit)制造超强性能的显卡;而G92和RV670则是采用新工艺、向成本(256Bit)妥协之后的产物,因为功耗发热得到了有效控制,这就使得双核心方案成为可能,双方不约而同地发布了基于G92和RV670的双核心显卡及其3/4路并联系统,在单GPU性能原地踏步的情况下,通过多核心并联的方式大幅提升了3D性能上限,为发烧玩家提供了更强悍的解决方案。
然而四颗GPU已经达到了电脑系统可以承受的极限,继续提升3D性能又遇到了瓶颈,现在就必须重头来过,想方设法继续提升单GPU的实力。沉寂许久之后,新一代怪兽级GPU诞生了,它就是拥有14亿晶体管的GT200!
Content end

● 8800GTX真正的接班人:GTX280





左:GTX280 右:9800GTX
第一眼看到GTX280显卡正面,感觉造型方面与9800GTX非常相似:全覆式的散热器外壳将显卡裹得严严实实,风扇位略显凹陷,这种设计的好处就是组建SLI或3路SLI时,即便两块显卡紧紧埃在一块,风扇也能吸入空气进行良好的散热。
● GTX280的背面酷似9800GX2



左:GTX280 右:9800GX2
显卡背面也安装了外壳,从这个角度看的话跟双核心9800GX2的造型又有些相似,当然这只是表象而已,如果将散热器和外壳拆掉的话,就可以发现GTX280显卡实际上最像8800GTX/Ultra。
● GTX280的PCB最像8800GTX


左:GTX280 右:8800GTX
可以看到,GTX280的核心安装了保护盖,输出部分被单独设计了一颗芯片安装在了接口附近,还有供电模快的设计,这些都与8800GTX/Ultra的PCB设计方案如出一辙!看来GTX280才是8800GTX的正统接班人!
第16页
GTX280实力虽强,怎奈双拳难敌四手,3D图形性能宝座被HD4870X2无情的夺走。当时业界普遍认为此次NVIDIA根本没有机会反败为胜,因为庞大的GT200核心功耗发热太大,加上512Bit显存布线过于复杂,不可能使用两颗GT200核心制造双核心显卡来与HD4870X2相抗衡,但NVIDIA却做到了……
● 2009年01月 55nm王者GeForce GTX 295震撼发布
GTX280登上加冕还没有多久,AMD就推出了双核心的HD4870X2,将GTX280从性能宝座上逼了下来。虽然说用双核心与单核心对阵并不公平,但是性能宝座的名头却无法改变。2009年01月,NVIDIA以牙还牙,推出了双核心的GTX280显卡——GTX295,目标很明确:让HD4870X2下课!
GTX295和上一辈双核心显卡一样,都采用了双PCB双核心的结构,下图就是GTX295结构的立体图。

从图上可以看出,这个结构有点类似于三明治的结构,两片PCB将硕大的散热器夹在中间,结构看起来有一些怪异,但是但从两颗核心之间来说,避免了两颗核心距离太近引起的高温。

同时从另一个方面来讲,这样的设计正好可以只是采用一个散热器,就能满足两颗核心的散热,散热器的正反面都被两片PCB仅仅夹住,核心与散热器接触的部分采用纯铜材质,更加有利于导热,而两片PCB上的显存也都有相应的散热措施。这样的设计有效利用了散热器、显卡的面积,同时也减小了显卡的体重。但是,这样的设计对于散热器与显卡PCB的工艺要求相当高,而且这也是纯粹的专用散热器,成本势必高出很多。

GTX295三明治平面图
和9800GX2类似,GTX295仍然是通过一个类似于SLI桥的排线让两颗核心进行数据交换,而将两颗核心的数据进行运算、任务分配等都是由一颗桥接芯片来完成。

GTX295的两张PCB一张为主PCB,另一张为副PCB,主PCB上包含一颗核心和一颗IO芯片、一颗桥接芯片,并且带有SLI接口,用户可以使用此SLI接口组建Quad SLI;而副PCB上则没有桥接芯片,只有一颗核心和一个IO芯片。
● 性能强劲 功耗合理
在绝大多数游戏中,GTX295的性能表现都凌驾于HD4870X2之上,两片GTX295组建的Quad SLI平台性能也非常强悍,但是在部分游戏中还是因为驱动程序不完善,导致成绩不正常。不过总体来说,因为驱动程序所导致的问题还是要比AMD的HD4870X2 Quad CrossFire少一些。实际上,对于这种多核心显卡平台,驱动程序是至关重要的。
在GTX295的身上,我们看到的不仅仅是当今最强大的单卡,也给我们带来了更多的新技术,如文章前面介绍的通过一块显卡做3D渲染、一款显卡做PhysX物理加速就是非常重要的一个方面。同时,64xQ FSAA与遮光屏蔽功能也同样值得称道。
另外,GTX295所采用的55nm工艺也让显卡的功耗大幅度下降。大家知道,GTX280的单卡设定功耗就高达236w,而双核心的GTX295,设定功耗仅289w!

GTX295的发布,标志着NVIDIA再一次坐上了性能王者的宝座。此前NVIDIA被HD4800系列低价上市打个措手不及,不得已只能通过杀价来维持市占有率。中端市场,被HD4850、HD4870钳制,而高端市场被HD4870X2夺走了“单卡之王”的称号。虽然当时发烧友迫切希望NVIDIA推出双芯GTX280领衔市场,但受限于工艺发热等原因,迟迟不见踪迹。而现在,随着55nm工艺的成熟,那个熟悉的绿巨人NVIDIA又回来了,工艺进步带来的热量大幅下降,将发烧友的梦想——双芯GTX280成为了现实。
第17页
如今GTX295这个怪兽已经是老树黄花,DX11时代来临ATI抢得头筹,HD5000系列风光无限,AMD已经提前布阵好了全线DX11产品,就等NVIDIA前来应战。可惜而NVIDIA方面的GF100依然是犹抱琵琶半遮面。GF100核心之所以延期这么久,一方面是因为NVIDIA遭遇了40nm新制程良率不足的困扰,另一方面GF100在核心架构方面的改进非常巨大,NVIDIA力图打造一颗在DX11和GPU计算方面都趋于完美的核心。
● GF100架构改进要点预览

如果说Cypress是“双核心”设计的话,那么GF100的流处理器部分就是“四核心”设计,因为其raster units(光栅化引擎)是以GPC(线程处理器簇)为单位的,一式四份。而raster units的功能就是以流水线的方式执行边缘/三角形设定(Edge/Triangle Setup)、光栅化(Rasterization)、Z轴压缩(Z-Culling)等操作。上页我们介绍过Cypress的Rasterizer和Hierarchial-Z双份的,而GF100则是四份的,虽然命名有所不同但功能是相同的。

另外,GF100拥有更多的PolyMorph(多形体引擎),是以SM(流处理器)为单位分配的,拥有多达16组。多形体引擎则要负责顶点拾取(Vertex Fetch)、细分曲面(Tessellation)、视口转换(Viewport Transform)、属性设定(Attribute Setup)、流输出(Stream Output)等五个方面的处理工作,DX11中最大的变化之一细分曲面单元(Tessellator)就在这里,因此GF100的理论Tessellation性能将会远超Cypress,因为Cypress只有一个Tessellator单元。

至于流处理器核心部分,则是经过了重新设计,与GT200/G92/G80相比是焕然一新,因此NVIDIA将其称为CUDA核心而不再是流处理器。
GF100的512个CUDA核心都符合IEEE 754-2008浮点算法(Cypress也是如此)和完整的32位整数算法,而后者在过去只是模拟的,事实上仅能计算24-bit整数乘法;同时全面引入的还有积和熔加运算(Fused Multiply-Add/FMA)。此外双精度浮点(FP64)性能大大提升,峰值执行率可以达到单精度浮点(FP32)的1/2,而过去只有1/8,AMD从R600开始到现在的Cypress核心都是1/5,没有做任何变化。

至于显存控制器方面的改进,还有显存ECC等外围功能就不多做介绍了。总而言之,GF100核心是GPU自从进入DX10时代以来,架构变化最大的一次,在GPU图形架构和并行计算架构方面都有了革命性的进步,因此备受玩家和业界期待。



GTX 480谍照
NVIDIA对于尚未发布的新品一直都比较低调,但整个业界还有玩家对于GF100都抱有很高的期望,因此不断的有相关产品技术资料还有产品实物图被曝光。现在据可靠消息表明GF100架构的GTX480显卡将在本月26日准时发布,届时我们将会为大家献上全方位的架构分析及性能评测,让我们一同期待吧!■
